【工业界】推荐系统课程
Bilibili:Wang Shusen
链接:推荐系统公开课——8小时完整版,讲解工业界真实的推荐系统
(可以结合笔记进行复习,不理解的内容直接跳到对应视频坐标)
推荐阅读(关于推荐系统的找到的比较好的读物)
笔记
推荐系统算法的过程:
- 召回
- 粗排
- 精排
- 重排
- 具体实践中,要对多种推荐算法机制进行测试,如何在有限的用户流量中进行测试?分层实验(同层互斥、多层正交),holdout对照组
召回
不同的召回通道?
基于商品的协同过滤ItemCF
使用两个索引进行召回
如何使用索引进行召回?
- 对每个用户ID记录其最近浏览的n个商品
- 对每个商品记录其最相似的k个商品
- 这种方式:索引的记录的更新是依赖离线计算的,而对用户推荐的线上计算量很小(nk)
ItemCF使用不同用户对同一种商品的喜好作为商品相似度的衡量,会导致一种问题:哪些毫不相关的商品但是被同时被分享到一个小圈子(例如微信群)中,会同时被这些用户所关注(点赞/收藏),导致明明毫不相关的商品却拥有高相似度。
如何解决?swing模型,两个用户倘若喜欢的商品的重合度高,那么很可能在一个小圈子中,其对于商品相似度的贡献权重设置为低。
基于用户的系统过滤UserCF
- 主要的思想是:对于不同用户,计算两个用户间的相似度(使用喜欢商品的相似度来衡量)
- 需要降低热门商品的权重
- 建立索引的方法:
- 用户-用户索引:找出对给定用户的最相似k个用户
- 每个用户的last-n商品
- 一共nk个商品
最近邻召回时复杂度过高?使用近似最近邻算法,使用桶哈希局部区域的item(相当于聚类);
- 余弦相似度就是:向量归一化后的向量内积相似度
双塔模型(工业界常用):
用户塔 + 物品塔
分别对用户和物品进行embedding,输出两个向量,使用向量计算相似度;余弦相似度作为用户对物品的兴趣预估值。
在计算了向量后,可以使用近似最近邻找到目标的物品
正样本 / 负样本 / 采样
正样本:被点击过的样本
简单负样本:没有被召回的样本(几乎是全体物品)
困难负样本:被召回但是没有进入精排的样本/被曝光但是没有被点击的样本
困难负样本标志着用户可能感兴趣(被召回),但是没有实际点击的样本;它不能用于召回模型的训练,而只能用于排序模型的训练;
如何进行训练?
- 选择样本:pointwise;pairwise;listwise
如何进行线上推荐:
- 离线存储物品向量:实现通过神经网络计算物品向量,并存入向量数据库和建立索引
- 在线计算用户向量(因为用户特征可能是动态变化的):近似最近邻查找
模型的更新?全量更新;增量更新
双塔模型+自监督学习
推荐系统的头部效应严重:少部份物品占据绝大部分点击,从而学到较好的表征;但是大部分低曝光物体的表征学不好
自监督对比学习【Contrastive Learning】方法:(Google提出/小红书应用效果很好)
对比学习的核心思想是将相似的样本(正样本对)拉近,将不相似的样本(负样本对)推远。通过这种方式,模型能够学习到样本的有用特征,使得相似样本在特征空间中靠近,不相似样本远离。
- 学习方法如下图所示:

- 双塔模型+自监督学习的训练过程:
- 由于加上第二项自监督的对比损失,有利于冷启动/低曝光的物品参与模型训练(否则如果只有第一项双塔模型的损失,低曝光物品几乎没有机会被训练)。

Deep Retrieval【深度检索】
来自 ByteDance【Link】Deep Retrieval: Learning A Retrievable Structure for Large-Scale Recommendations
相关blog阅读📖 (TDM 三部曲以及DR)
- 索引结构是一个 $K*D$ 的矩阵,总共有 $D$ 层,每层 $K$ 个节点,如下图(a)所示,$d$代表路径的深度,$K$代表海量物品的个数;
- 路径:一条路径指的是一条物品序列【suchas:3-4-1】
- DR通过输入用户特征向量,得到 $P(path|user)$ 【如下图(b)流程所示】,表示对于特定用户的,选择某条物品路径的可能性。
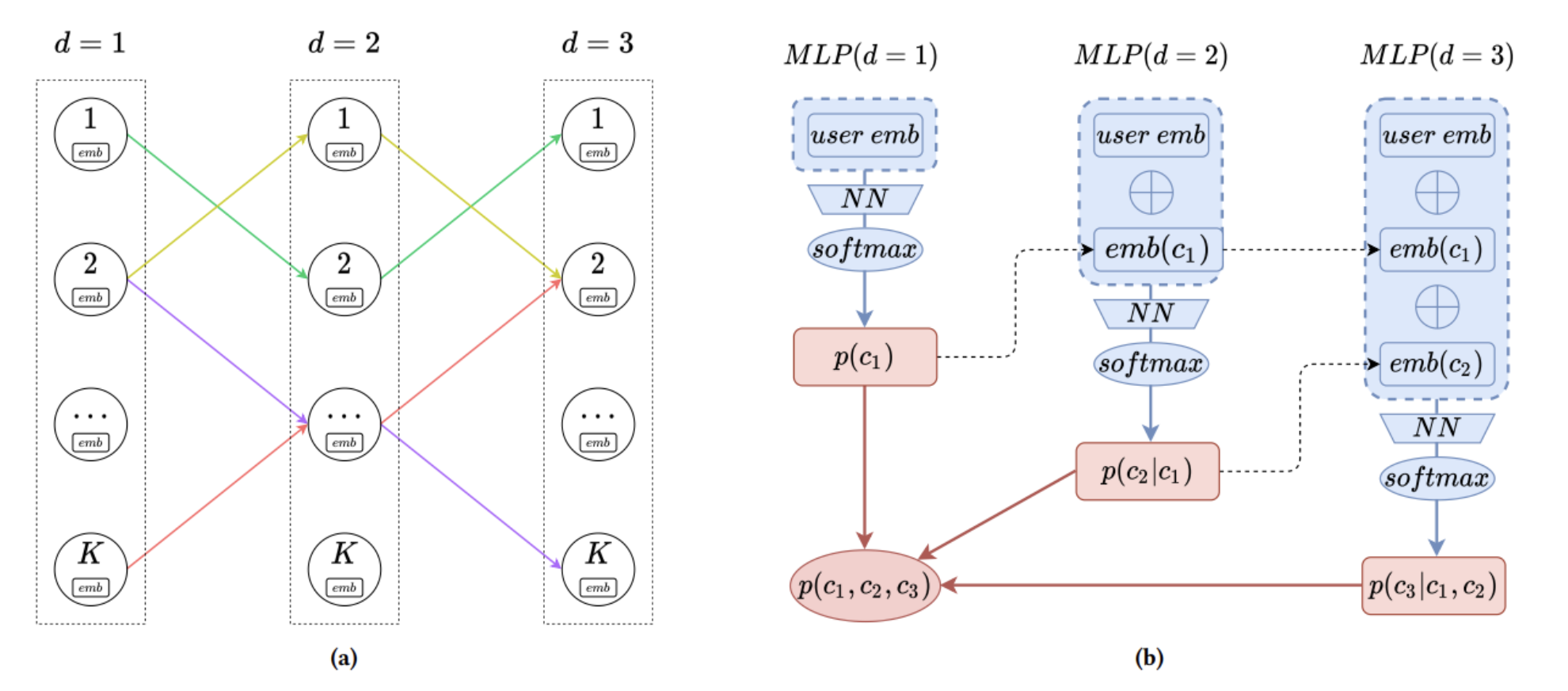
- 通过 beam search 束搜索贪心选取beamsize条路径,作为召回的所有物品。具体完整的召回过程如下图所示。

模型的训练:
同时学习 【用户-路径】以及【物品-路径】之间的关系。
训练【用户-路径】索引,即给定用户可以匹配多条路径;
如何进行训练?可以通过用户点击过的物品,找出该物品对应的路径;就匹配了一个用户和多条路径,对模型进行训练使得$p(path|user)$尽量大

训练【物品-路径】索引,即给定物品可以匹配多条路径;
如何进行训练?

其它召回通道
都可以通过维护索引进行实现
地理位置召回:维护【地理位置/城市->优质笔记列表】的索引进行召回。这样的召回没有个性化可言,但是如果和用户不匹配在排序中会被丢弃。
关注作者/交互作者/相似作者召回:
缓存召回:精排后没被曝光的物品不能直接浪费 / 缓存需要退场替换机制(存留天数/是否被曝光/缓存次数…)。

曝光过滤 & Bloom Filter
由于两次刷新的间隔可能很短,所以有很高的实时性要求
曝光过滤:对用户已经曝光过的物品不能再进行推送
实现:通过记录最近曝光过的物品-曝光列表
限制:召回数千个物品,如果对物品进行一一匹配是否在曝光列表中【也有数千个物品】,复杂度过高
解决:Bloom Filter:【一种数据结构】
思想:维护一个二进制向量m bit;$k$个哈希函数,对每个已经曝光的物品进行$k$次哈希;只要召回物品多次的哈希存在至少一个0就可以肯定一定没有曝光;存在一定误判的可能性【即未曝光误判为已曝光】
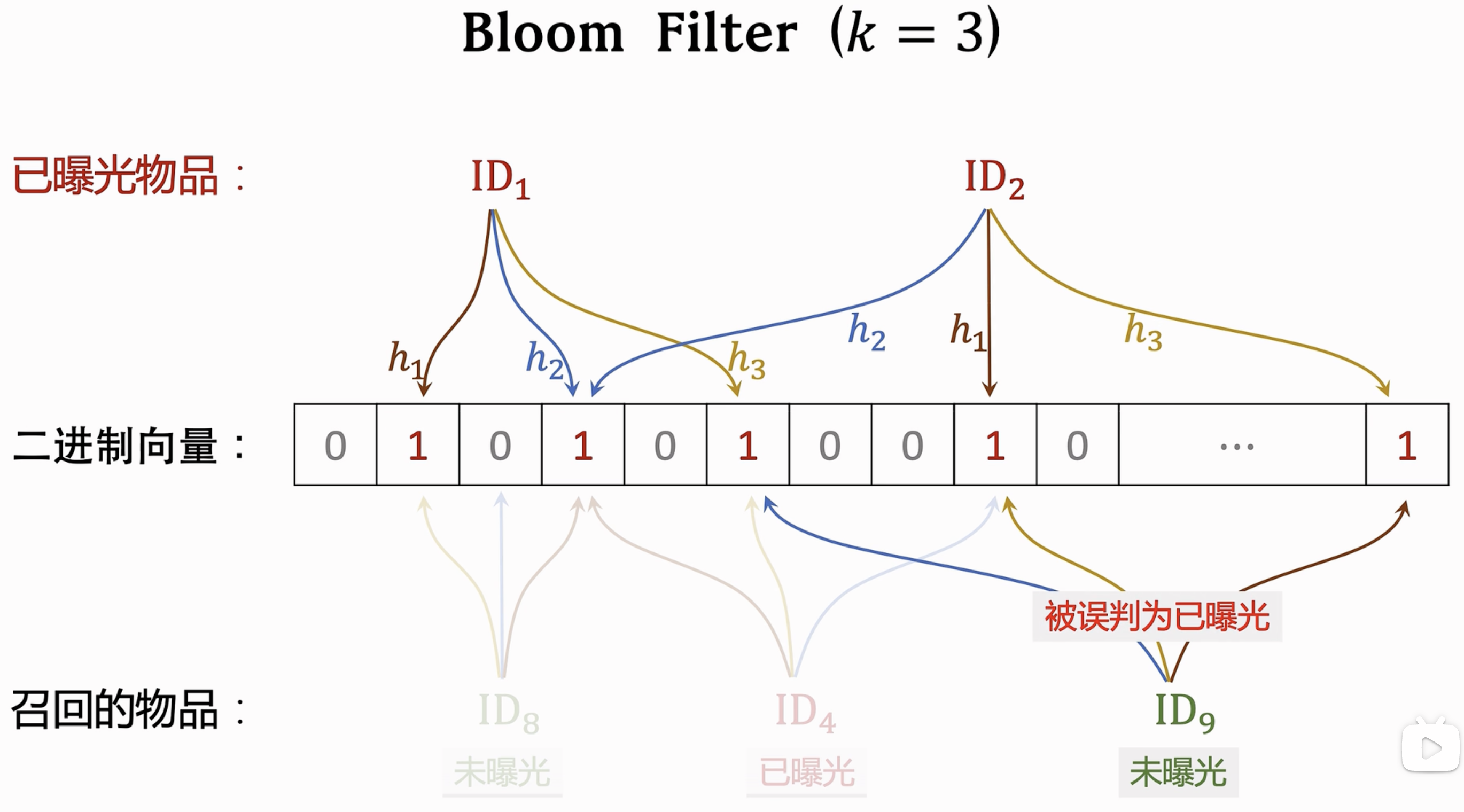
Bloom Filter参数选取:

排序
- 包括精排/粗排,这里不进行区分,因为是计算规模的区别;
特征信息
- 提高样本的特征覆盖率,有以下几个角度的特征信息,用于排序所需:

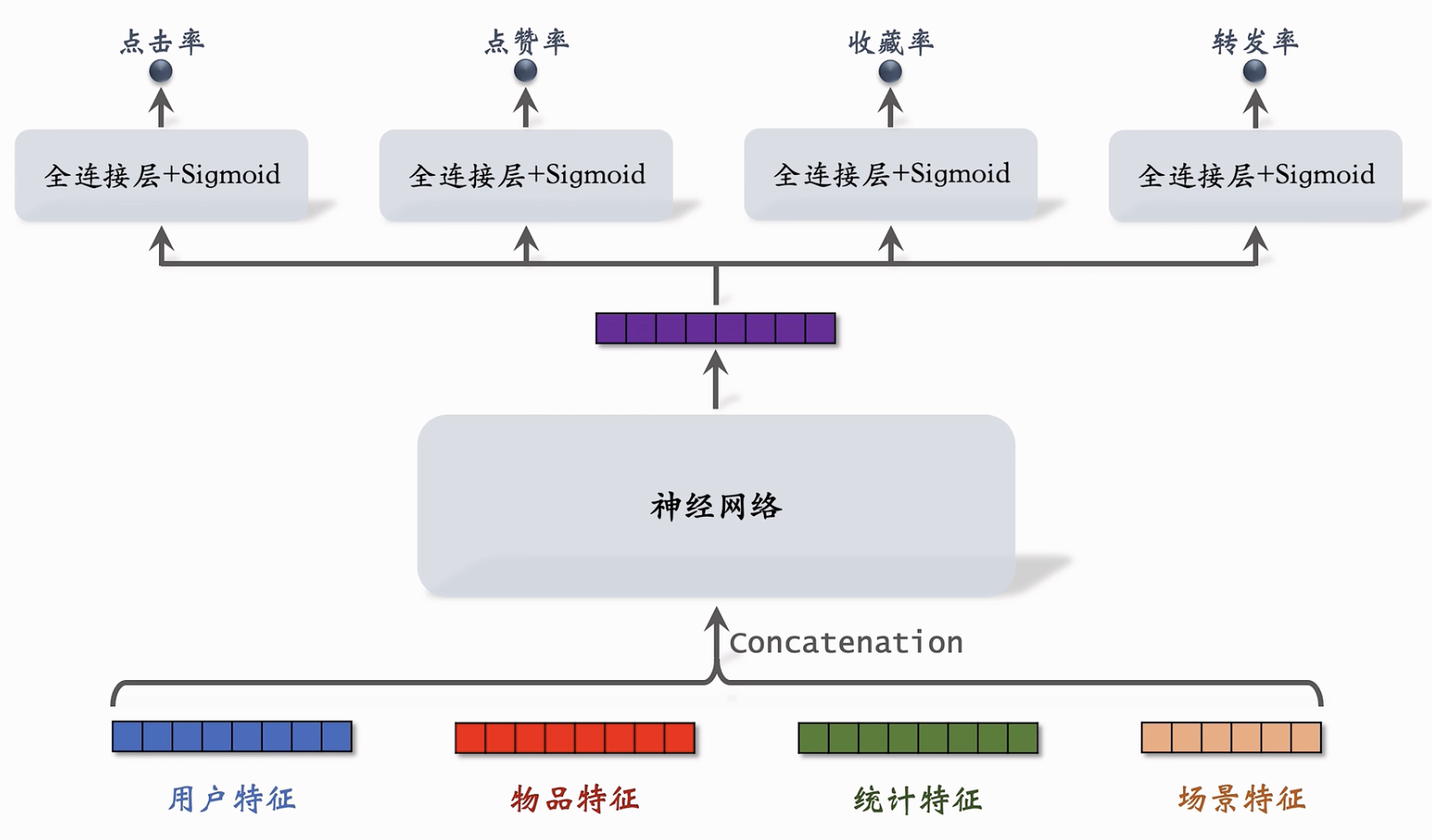
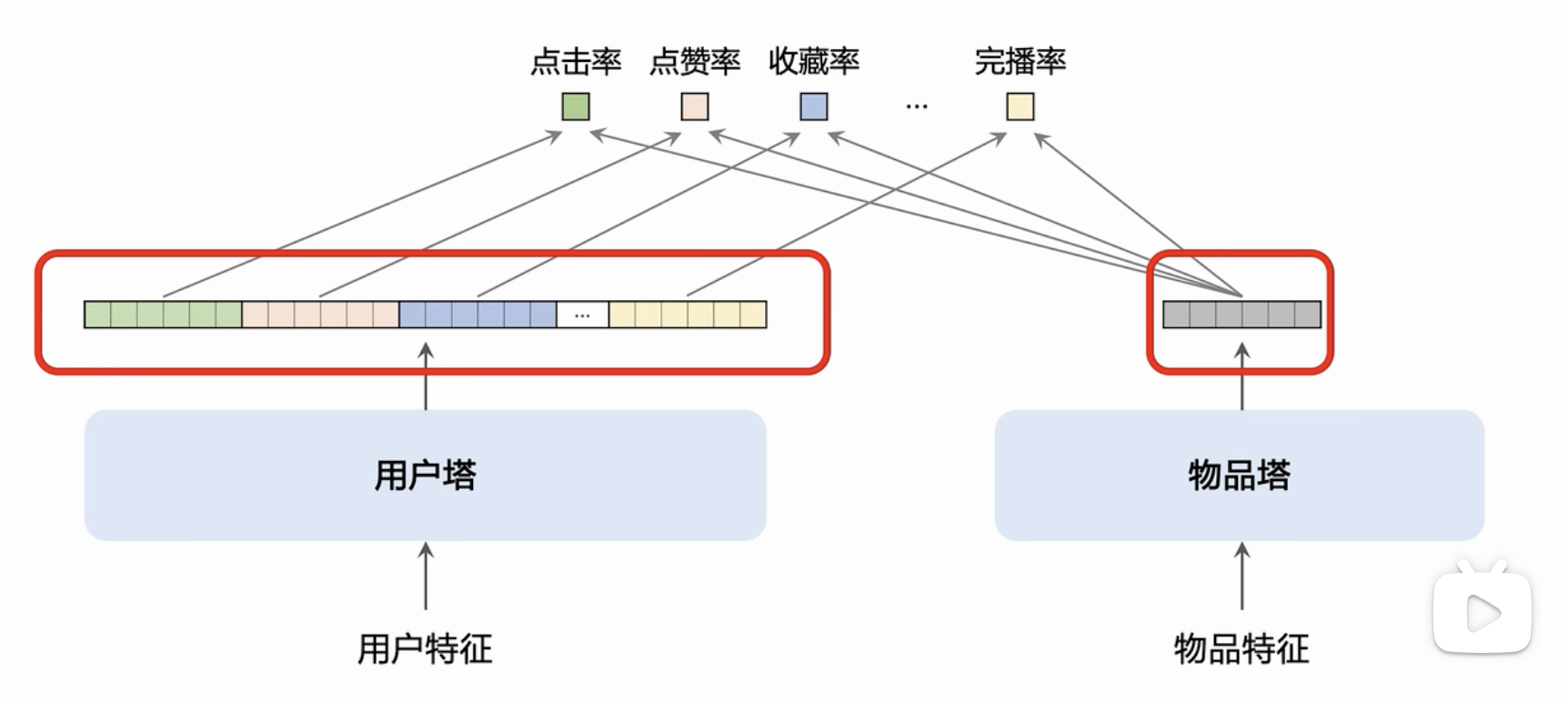
多目标模型
- 排序模型由一系列特征【包括用户特征等】通过神经网络预测点击率【包括收藏率、点赞率】,融合这些点击率的加权和作为排序分数
预估值校准
- 由于正负类别样本数不均衡【这里的正例是用户点击的物品,正例>>负例】,所有需要对负样本做降采样(downSampling)。
- 由于做了负样本降采样,所以 预估点击率 > 真实点击率(期望不一致)
- 令正样本数为$n_+$,负样本数为$n_-$,$\alpha$为采样率

Multi-gate Mixture-of-Experts【MMoE】
输入特征信息,使用不同的专家神经网络(Experts),输出专家投票向量;再使用特征信息输出不同的权重信息,使用该权重对专家投票做加权平均来预测不同的点击率;
上层结构:
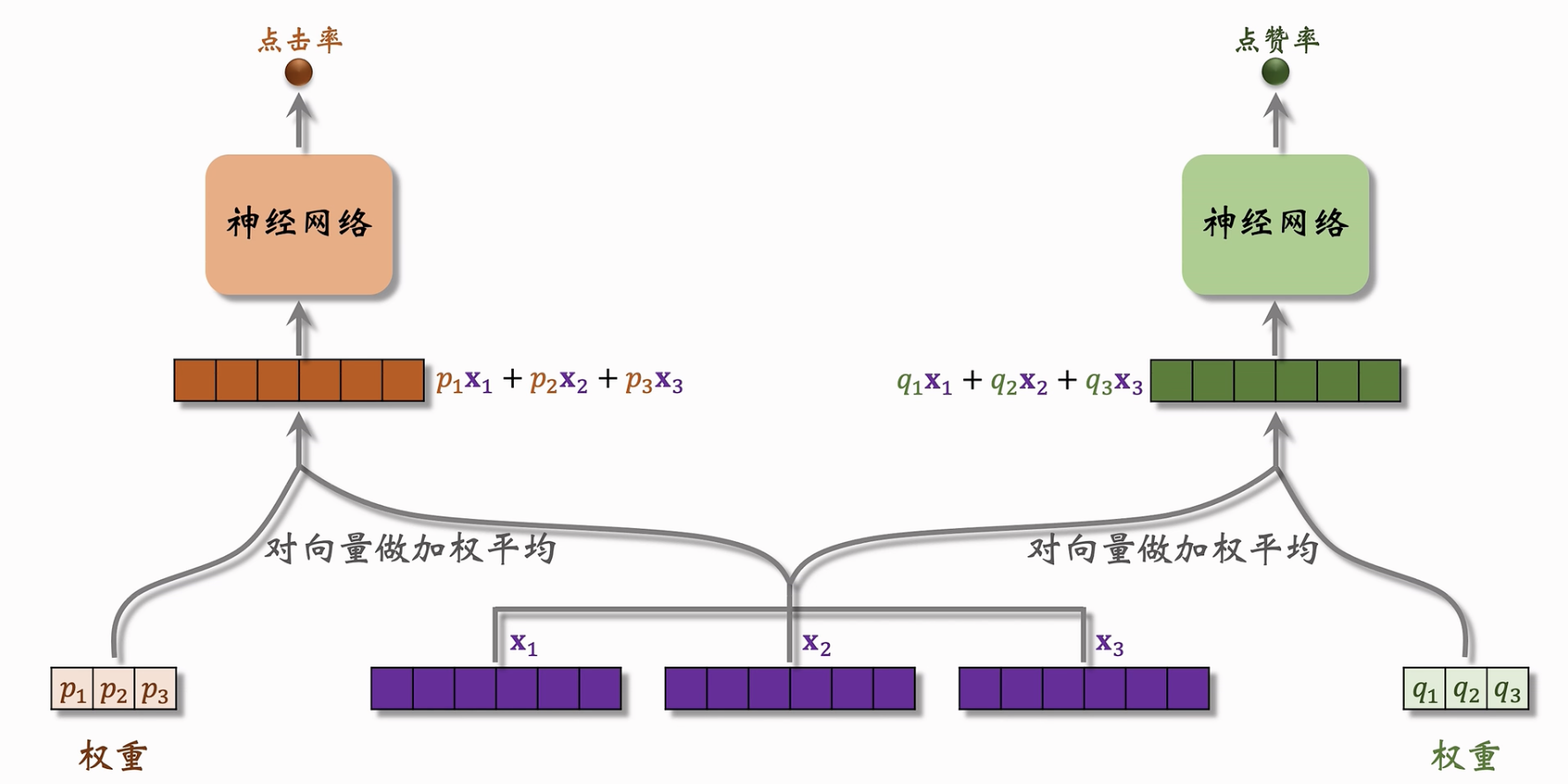
- 下层结构:
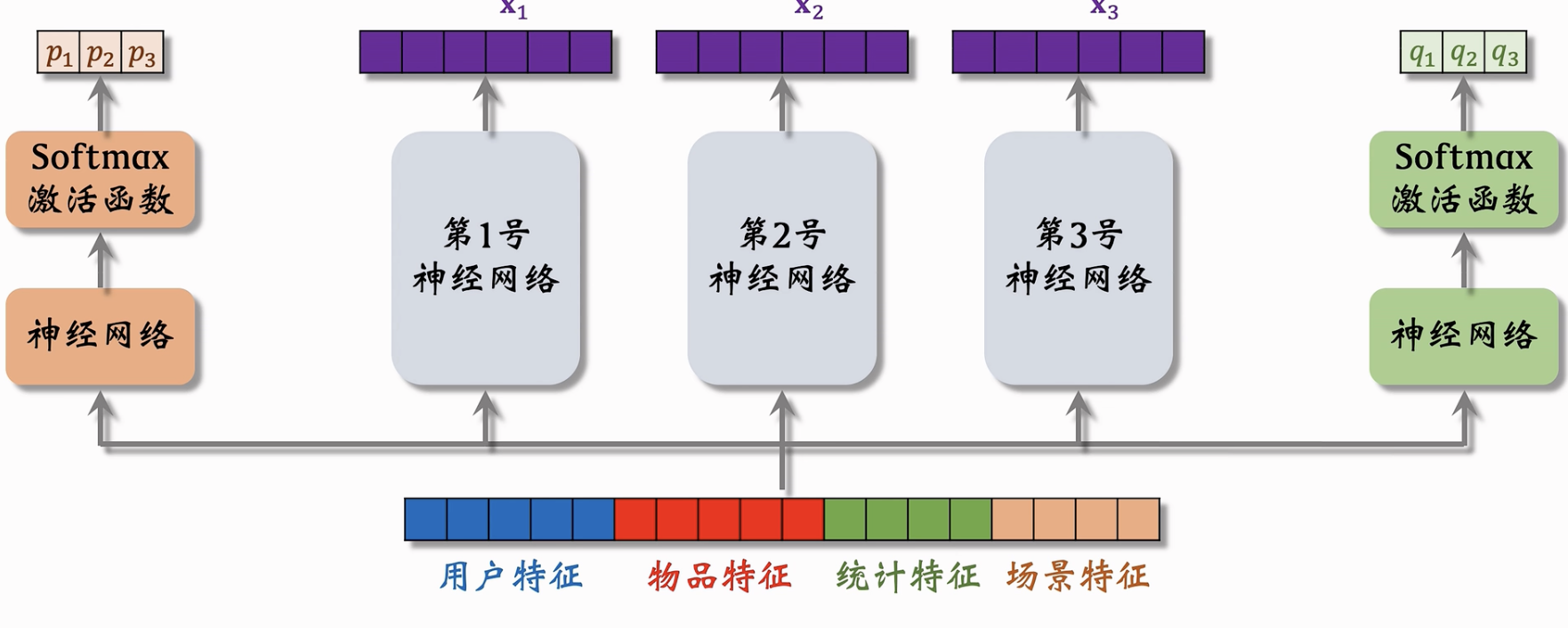
- 存在问题:极化现象(可以输出的权重信息过度极化,例如001,只考虑了第三号专家的投票信息,缺乏融合,性能较差)
- 如何解决?对输出的权重值使用 dropout 进行随机丢弃,即随机丢弃专家的投票信息,如何发生极化现象,那么当该极化的专家被随机mask时结果会出现显著偏移,从而避免了极化的出现。
粗排
实质上前面的模型使用精排,而不适用于粗排模型;因为其使用了特征的前期融合,开销很大。
对于粗排阶段,往往只有一个用户特征,很多物品特征,以及统计特征。
三塔模型:
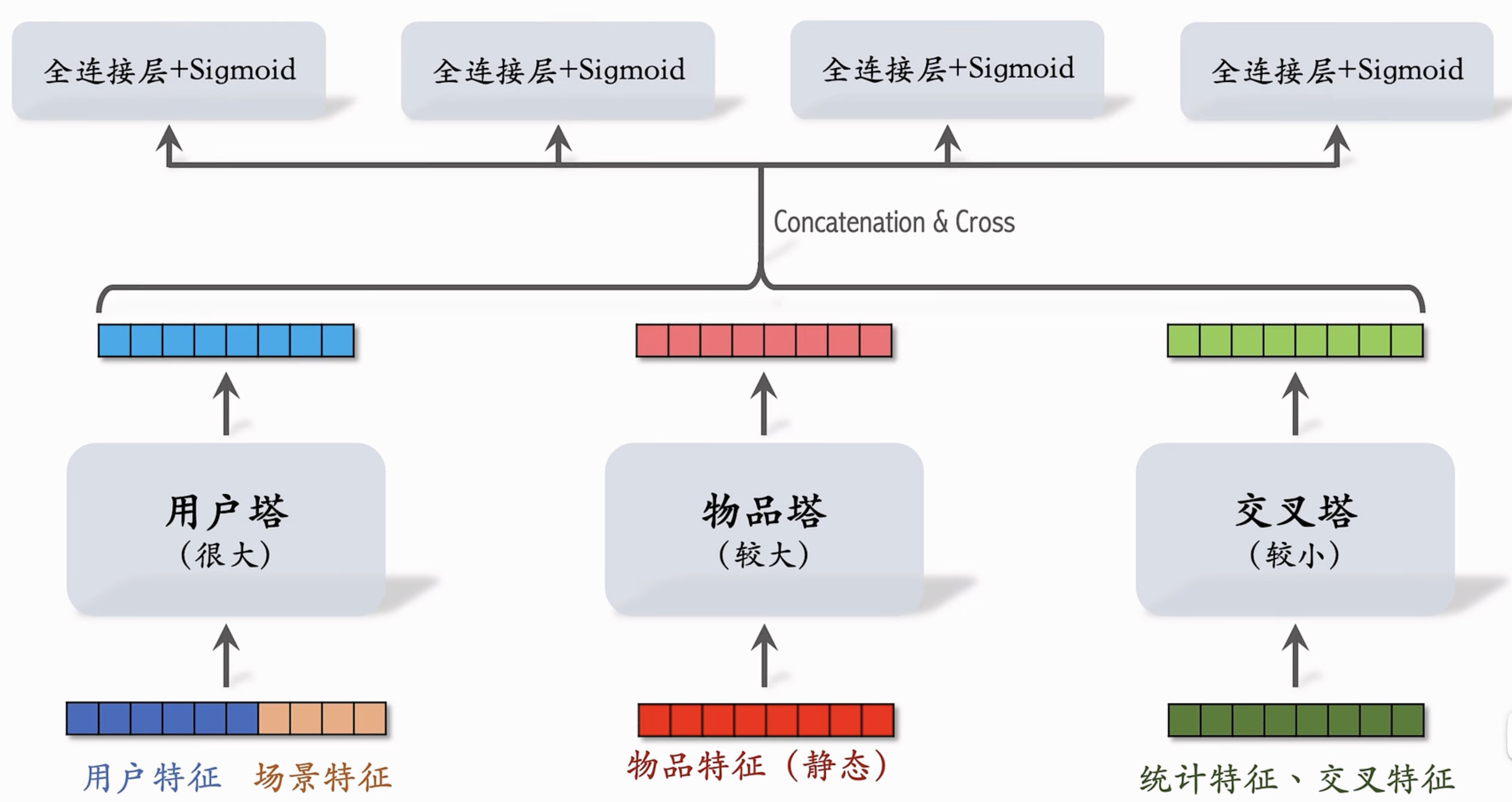
- 优势在于:对于用户特征可以很大,因为只做一次推理;对于物品特征由于相对静态可以进行缓存;对于动态的统计特征需要进行多次推理,因此使用较小的交叉塔。
- 三塔模型是后期融合,先推理和融合,因此开销较小。
特征交叉
- 概念:特征交叉(Feature Crossing)是机器学习中特征工程的一种技术,通过组合多个原始特征来创建新的特征。这些新特征可以捕捉到原始特征之间的相互作用,从而提高模型的表达能力和预测性能。
- 在推荐系统中,特征交叉是非常重要的一部分,它通过将用户和物品的不同特征进行组合,帮助模型更好地捕捉用户偏好和物品特性之间的复杂关系,从而提高推荐的准确性。
- 在召回和排序的过程都会用到特征交叉 ;
二阶交叉特征
- 如下图:d个特征进行交叉

- 存在问题?当d较大时,参数过多,导致过拟合问题;解决?使用Factorized Machine
Factorized Machine(FM)
- 把矩阵U进行矩阵分解,从而使得每一个$u_{ij}$为两个向量的内积
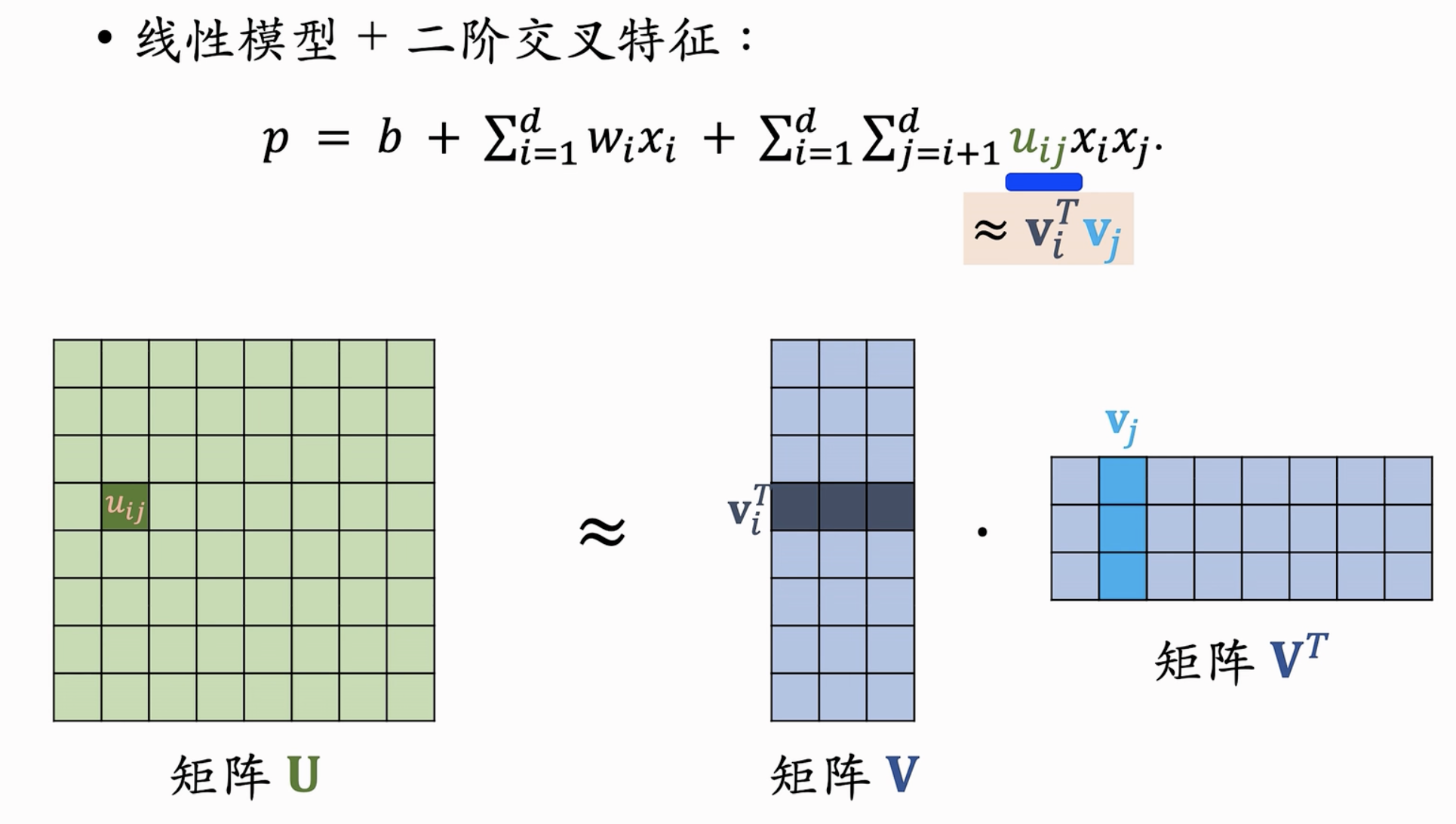
- 矩阵近似分解有效减少了参数数量

- FM是线性模型的替代品,即在线性模型后面加入二阶交叉特征(FM对二阶交叉特征进行矩阵分解-减少权重参数数量),增强其表达能力;
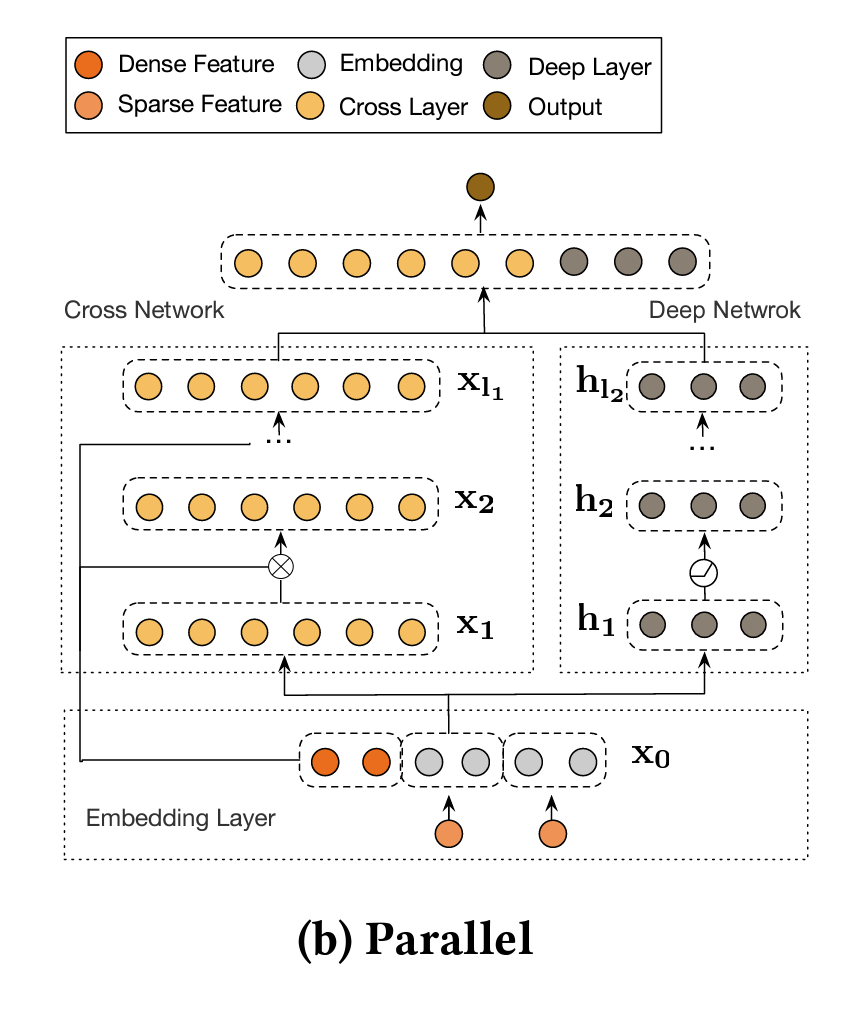
深度交叉网络(DCN,Deep & Cross Network)
论文🔗:Deep &Cross Network for Ad Click Predictions KDD2017-Google(过时)
改进:DCNV2:Improved Deep &Cross Network and Practical Lessons for Web-scale Learning to Rank Systems
- 前面内容在召回/排序的多种模型(例如双塔/MMoE等)中许多都使用了神经网络;简单来看,这些可以使用全连接的神经网络MLP;深度交叉网络是一种神经网络,用于替代全连接神经网络。
- 概念:一种用于CTR预测的深度学习模型,它结合了深度神经网络(Deep部分)和交叉网络(Cross部分),从而能够捕捉特征的高阶和低阶交互信息。DCN通过引入交叉层来增强特征的交互学习,提升了模型的表现。
核心结构:交叉层/交叉网络
交叉层是DCN的核心组件,设计用于高效地捕捉特征之间的交互关系。$x_0$和$x_i$作为一个交叉层的输入,对$x_i$进行全连接变换后,和$x_0$进行内积,最后加上$x_i$作为输出(这应用skip-connection的思想-抑制梯度消失),最后输出一个$x_{i+1}$。
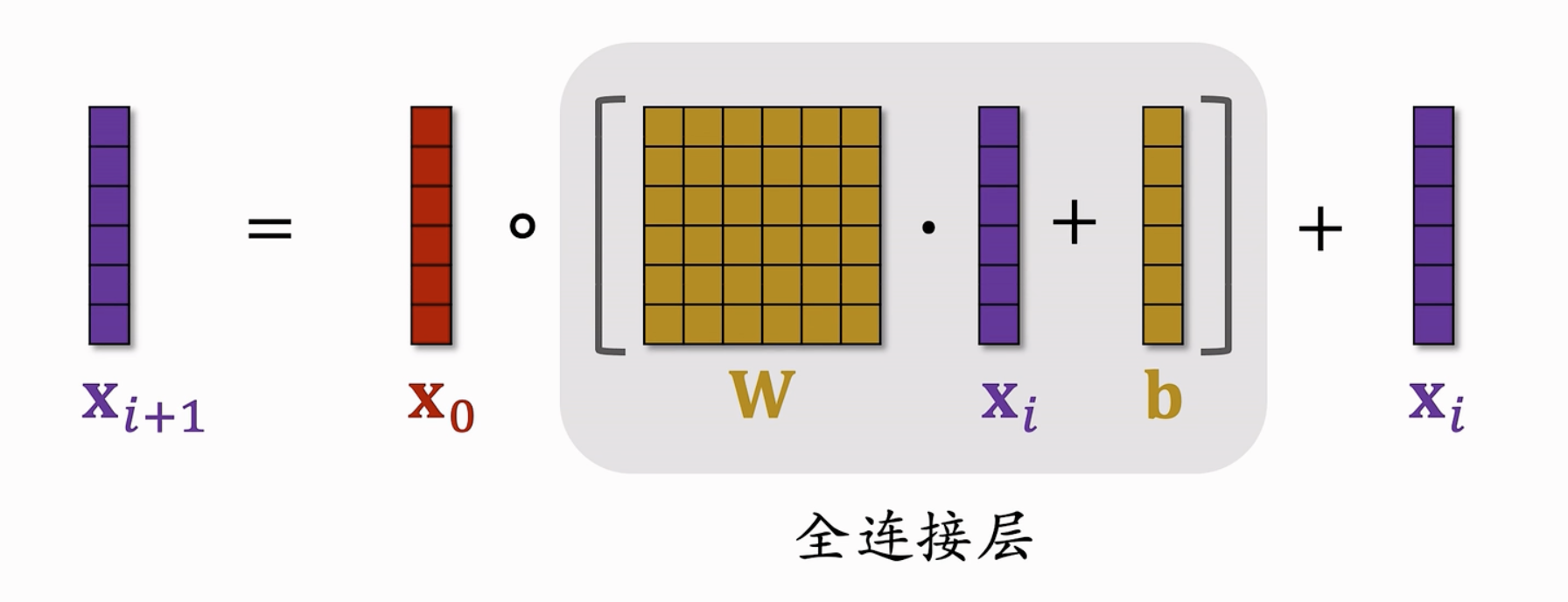
一个交叉网络串联多个交叉层
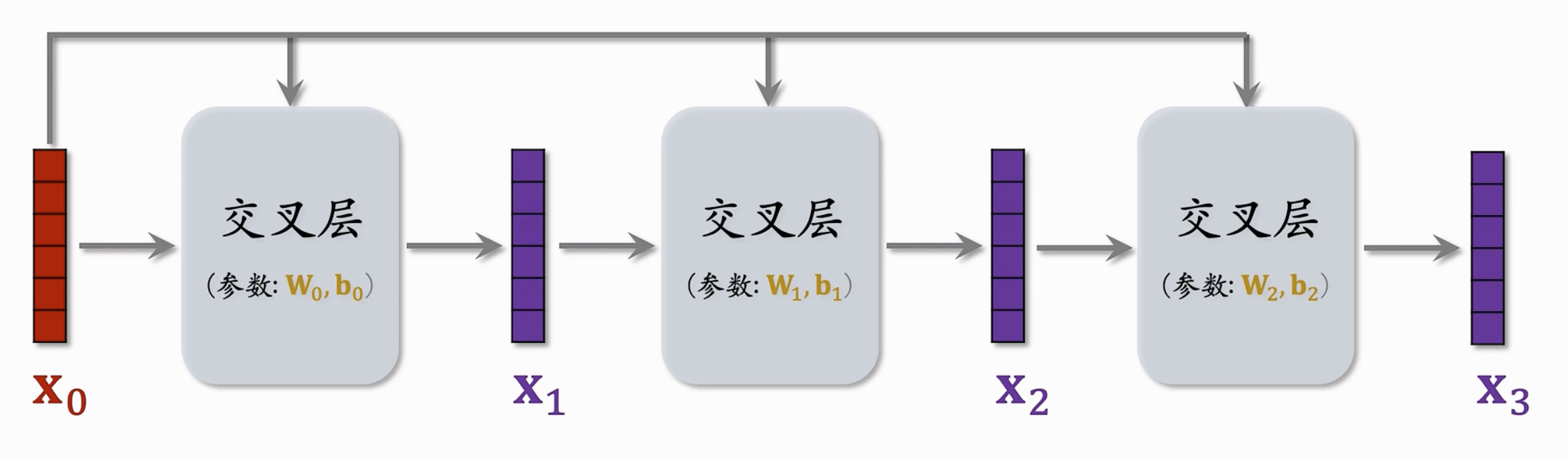
- DCN的工作原理
- 输入层:接受用户特征、广告特征和上下文特征,并将这些特征转换为嵌入向量。
- 交叉网络:输入层的嵌入向量传递给交叉网络,通过多个交叉层逐步捕捉特征的低阶交互。
- 深度网络:输入层的嵌入向量也传递给深度网络,通过多个全连接层捕捉特征的高阶交互。
- 融合层:将交叉网络和深度网络的输出进行融合,通常通过简单的拼接或加权和的方式。
- 输出层:融合层的输出通过一个全连接层,并使用sigmoid激活函数计算最终的点击率预测值。
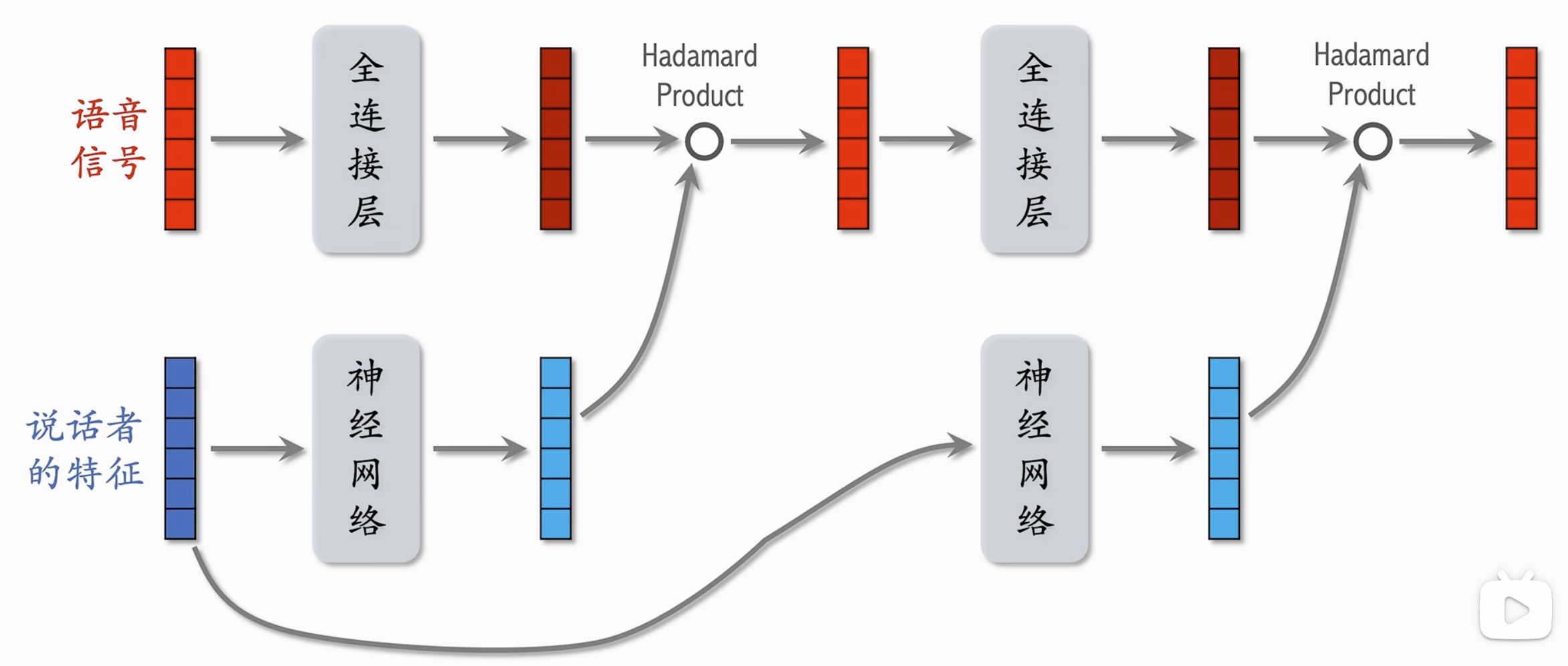
LHUC网络结构
- Learning Hidden Unit Contributions
- 在语音识别领域被提出,通过对说话者的特征进行建模,通过神经网络(最后一层为sigmoid层乘以2,即规约元素到[0-2]区间),从而对语音信号进行逐元素积(每个0-2的元素起到对语言信号放大/缩小的效果)
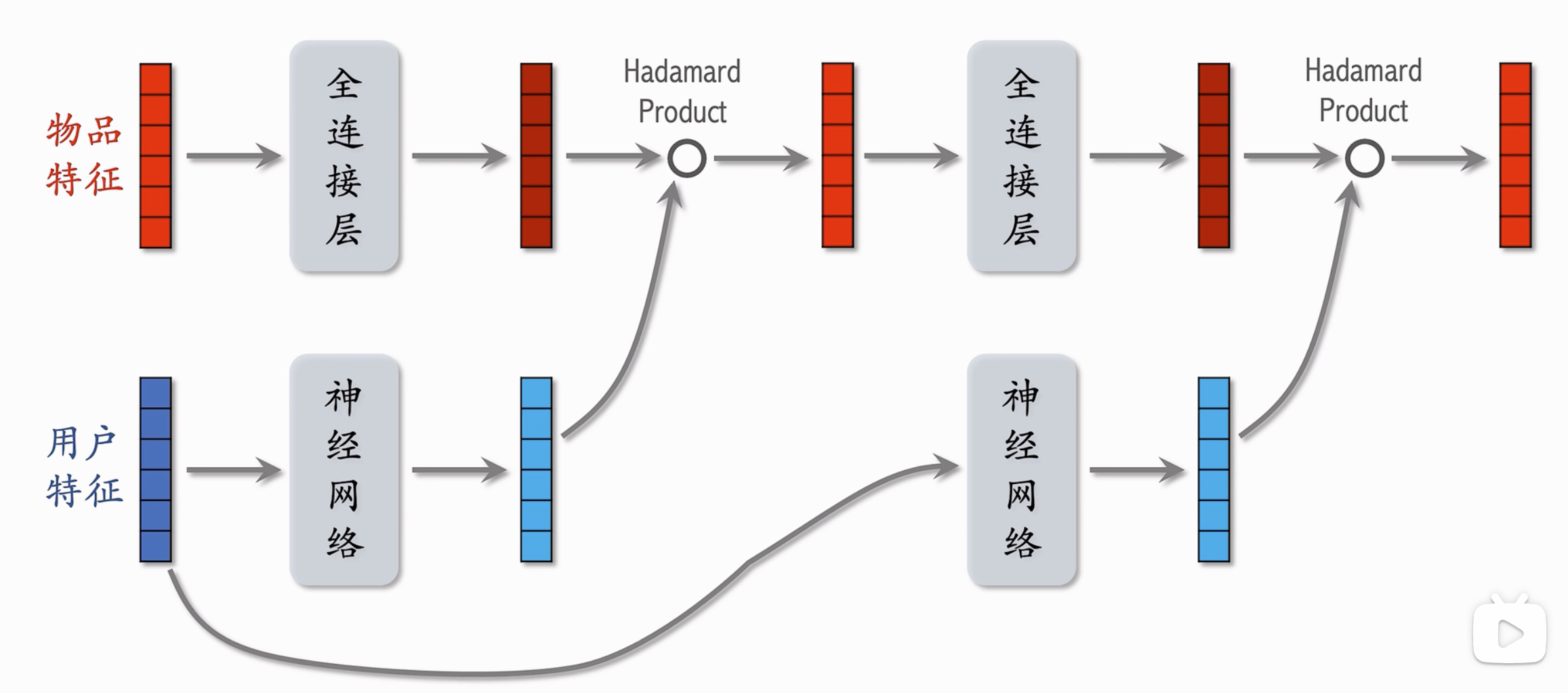
- 快手将思想运用到推荐系统中-PPNet
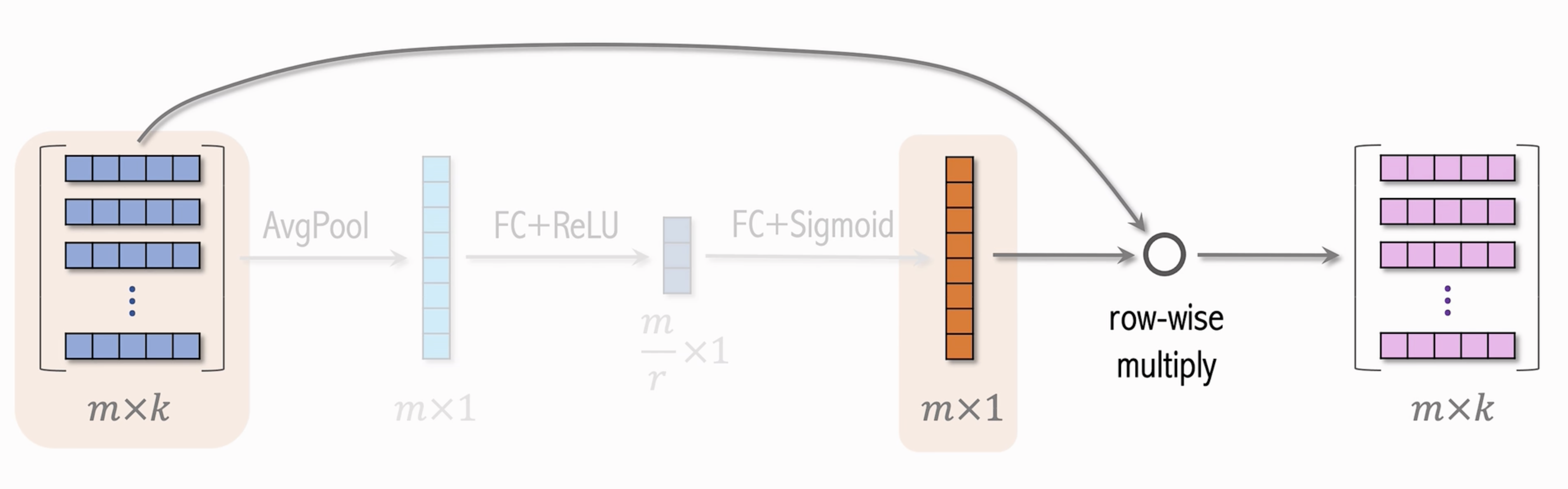
SENet
SENet (Squeeze-and-Excitation Networks)是一种用于图像分类和其他计算机视觉任务的网络架构,旨在通过自适应地重新校准特征通道来提高模型的表示能力。核心思想是引入一个“Squeeze-and-Excitation”模块,通过学习每个特征通道的重要性权重来增强特征表示。
工作原理
Squeeze操作:首先,对输入的特征图进行全局平均池化,生成一个全局的特征描述。这一步将每个通道的空间信息压缩为一个单一的数值,得到一个通道级别的特征向量。
$$
z_c = \frac{1}{H \times W} \sum_{i=1}^{H} \sum_{j=1}^{W} X_{c, i, j}
$$Excitation操作:然后,通过一个由两个全连接层组成的瓶颈结构(使用ReLU和Sigmoid激活函数)对这个全局特征向量进行非线性变换,生成一个用于重新校准每个特征通道的权重向量。
$$
s = \sigma(W_2 \delta(W_1 z))
$$重新校准:最后,将得到的权重向量按通道逐元素地与原始特征图进行乘法运算,得到重新校准后的特征图。
$$
\tilde{X}_c = s_c \cdot X_c
$$
运用于 RecSys的特征交叉中,通过S-E操作生成一个每个特征通道的权重向量,进行逐元素-向量乘积;不同的特征向量具有不同维数也同样适用;校准后的特征向量中较为重要的特征被放大和重视。
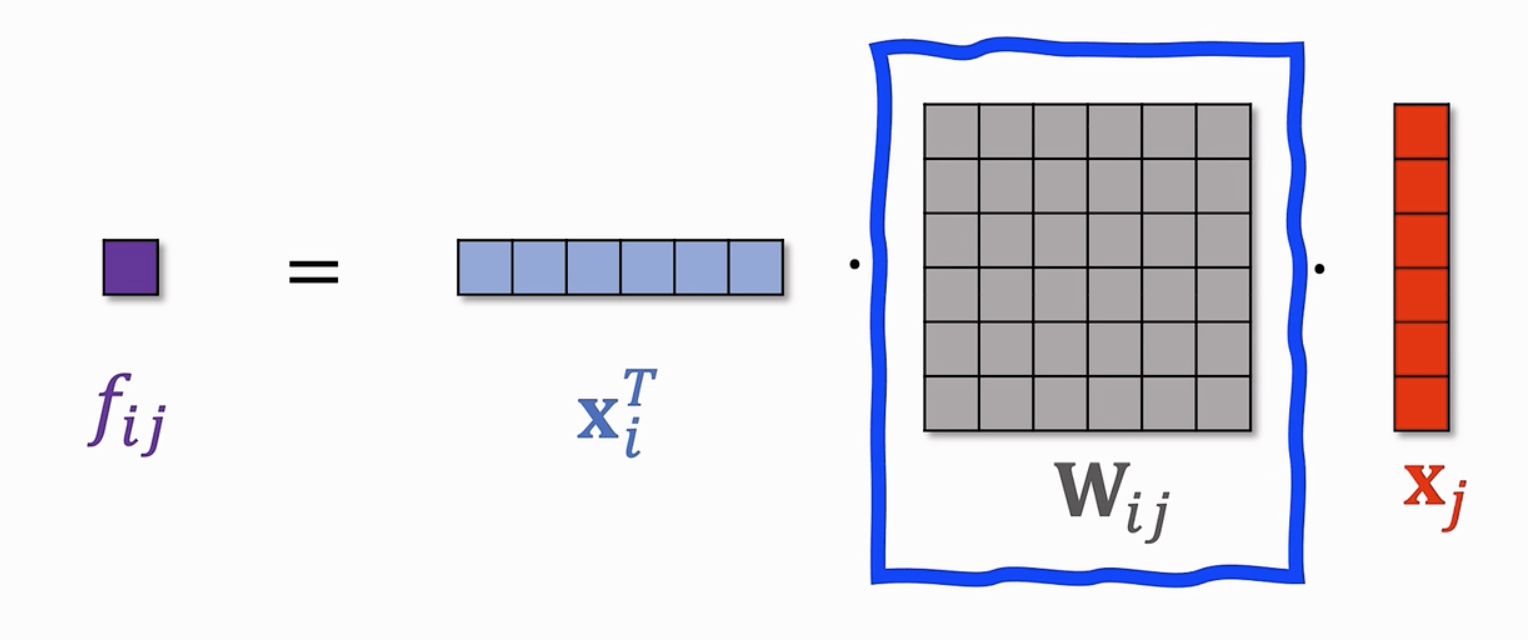
Bilinear Cross
常见的特征交叉操作包括:内积-生成一个实数;哈达玛乘积(逐元素乘积)-生成一个向量;
下面介绍:双线性交叉(Bilinear Cross)通过双线性操作,计算两个特征向量的交互关系。假设有两个特征向量 $\mathbf{x}$ 和 $\mathbf{y}$,每个特征向量包含多个维度。
$$
\mathbf{z} = \mathbf{x}^T W \mathbf{y}
$$
其中,$W$是一个可学习的权重矩阵,$\mathbf{z}$ 是交互后的特征表示。
- 另一种 Bilinear Cross:在使用矩阵-向量乘后使用哈达玛乘积
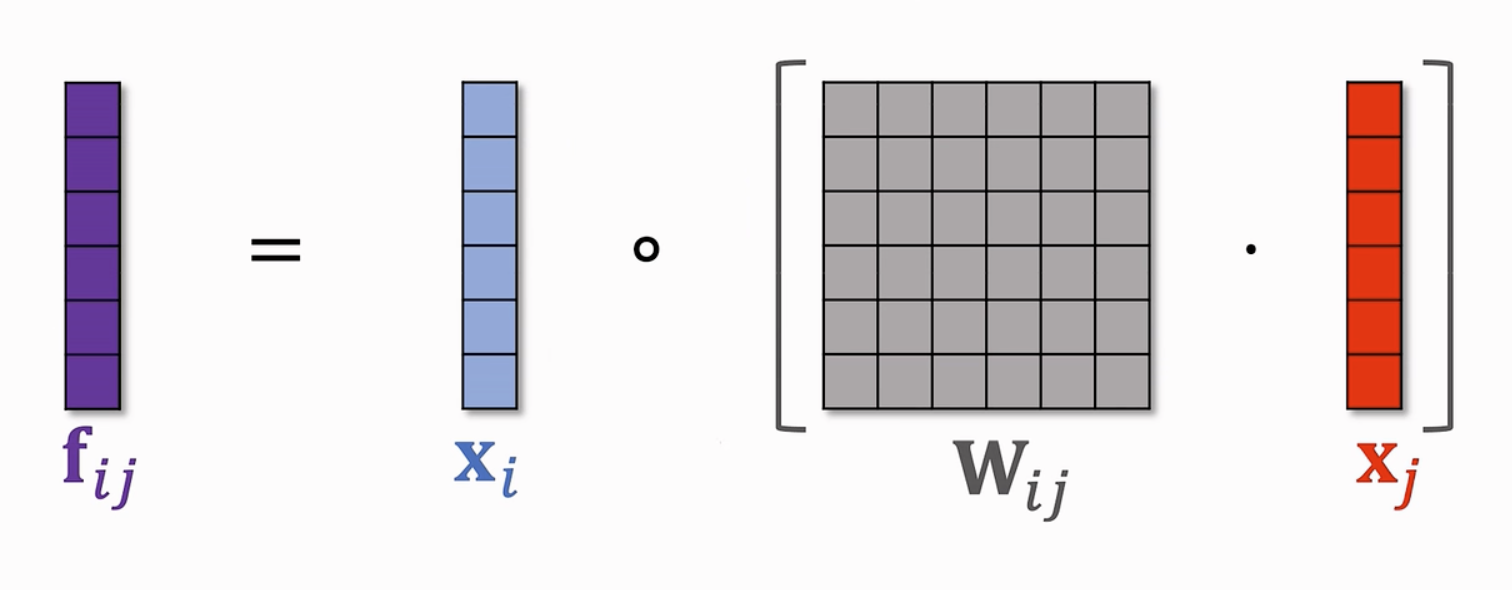
- 注意:由于每一次Bilinear Cross都需要训练一个权重矩阵,因此开销很大,需要选取部分特征向量而不是所有特征向量两两交叉。
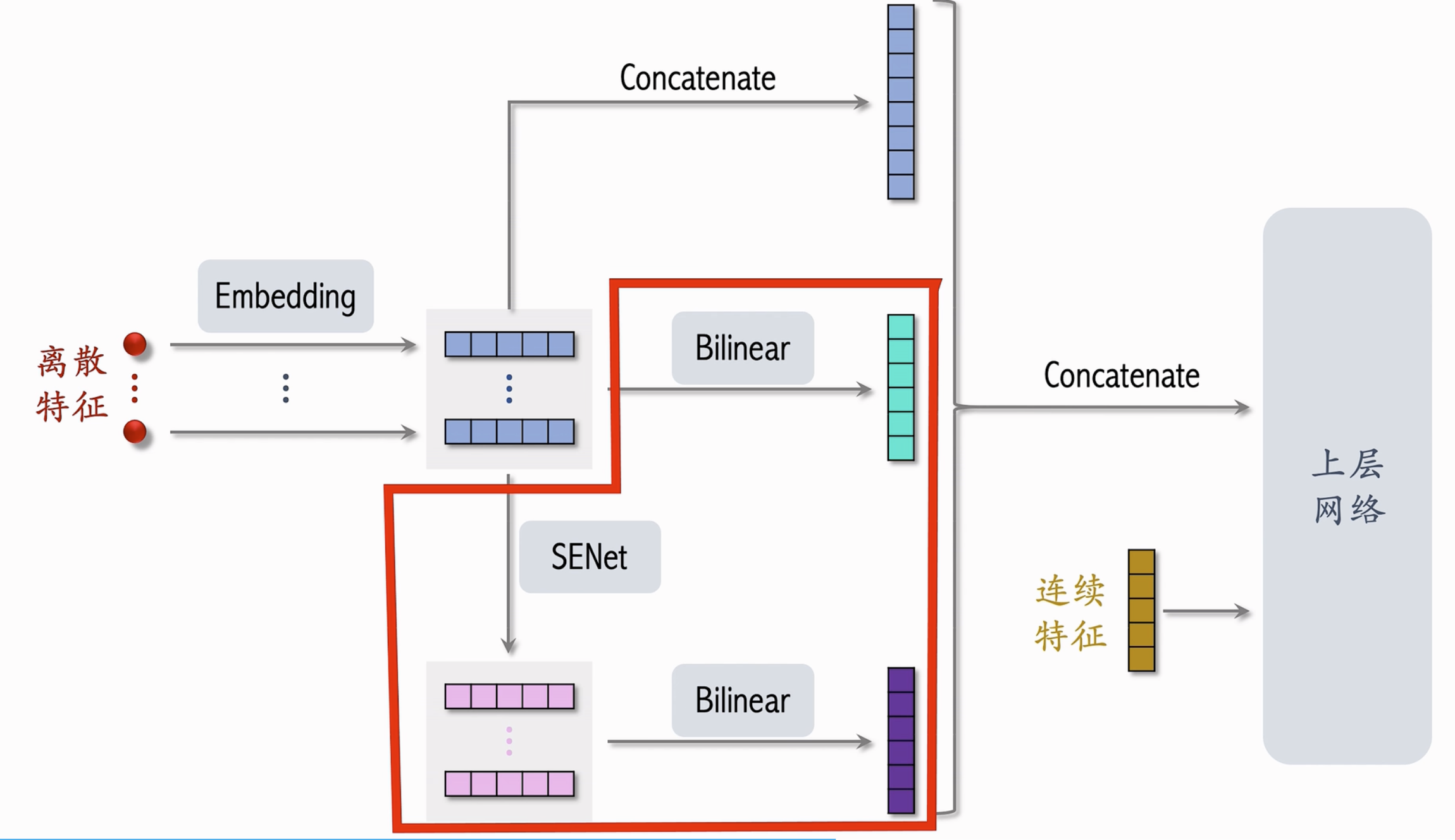
FiBiNET
使用了SENet+Bilinear Cross训练CTR模型
用户行为序列建模
基于用户的历史行为特征进行建模
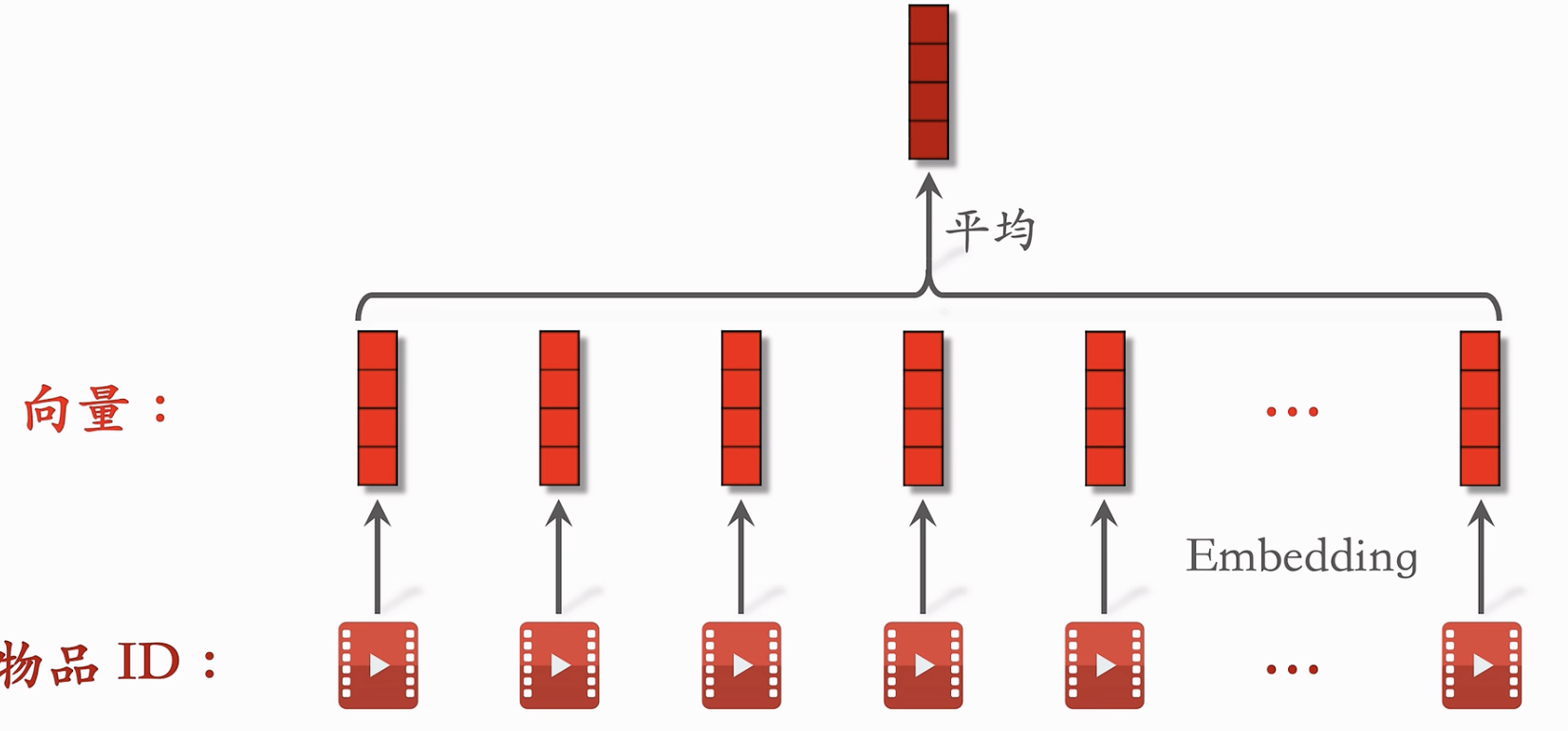
LastN特征

- 简单的方式可以对物品ID(可以包含物品的其他信息例如类目等)的嵌入特征进行平均
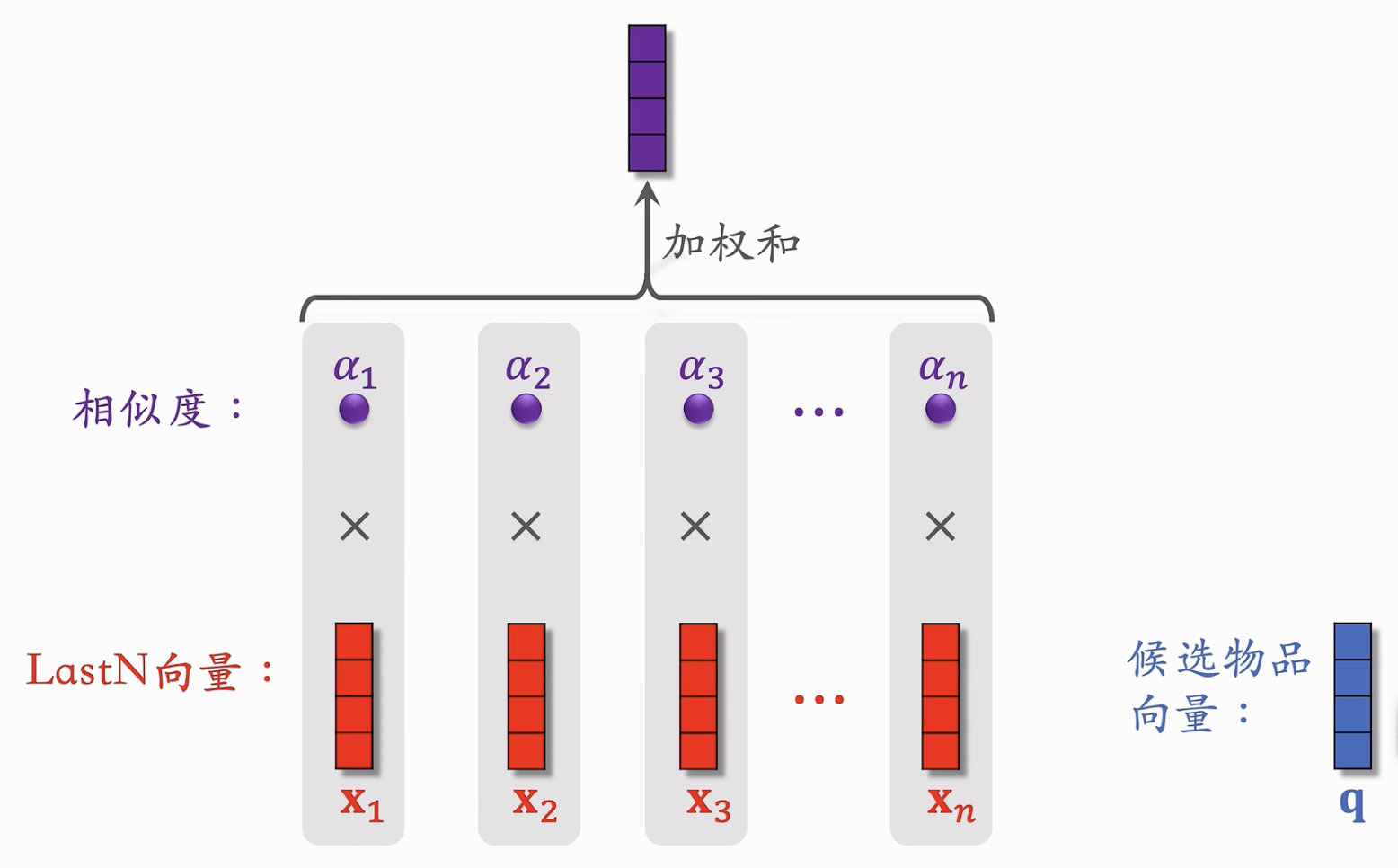
DIN模型
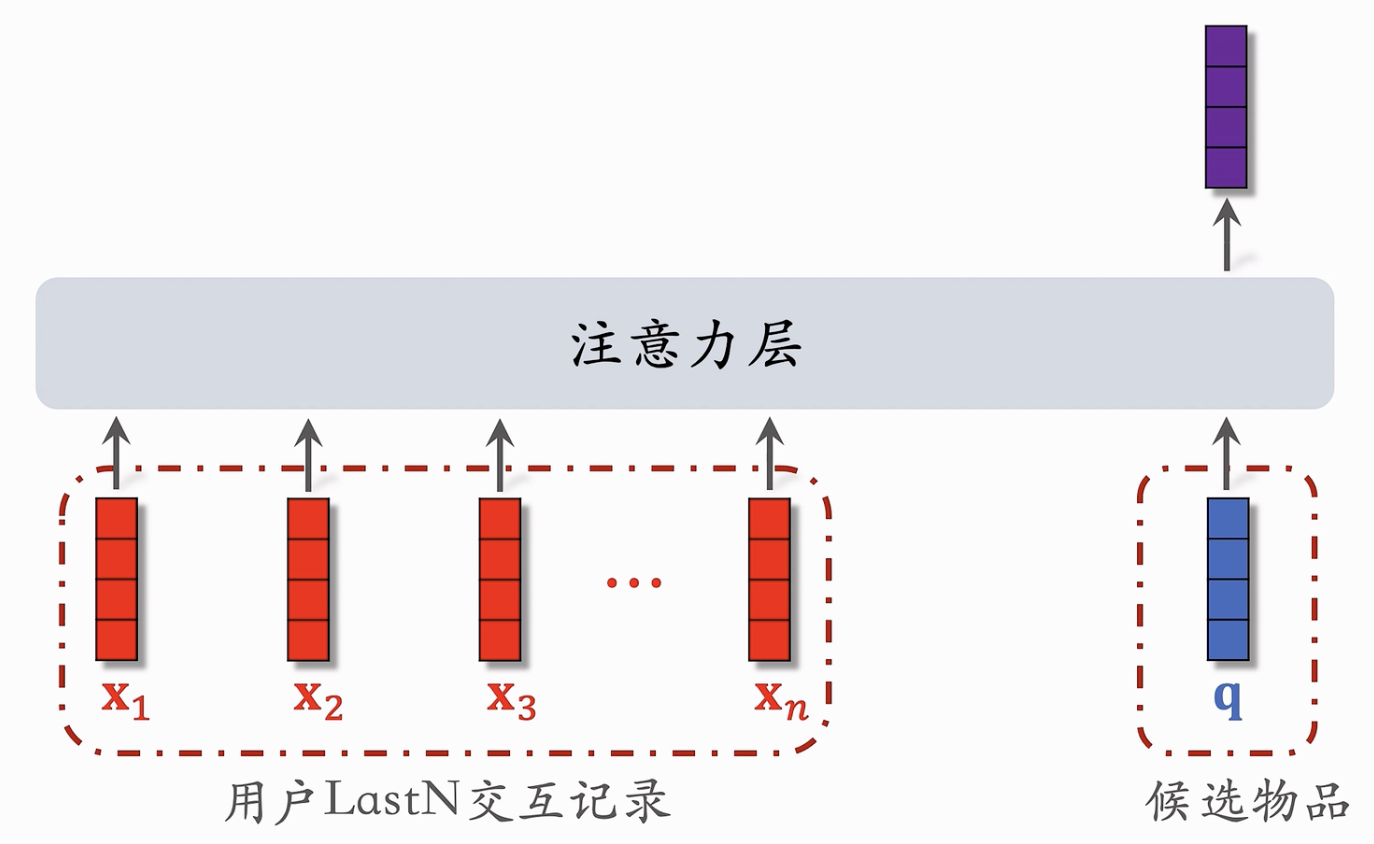
- 对物品的嵌入特征不使用简单的平均策略,而使用注意力机制:适应候选query向量和每个LastN向量(既是key也是value)计算相似度权重(可以使用内积等方法),然后计算加权和。
- 由于需要使用到候选物品向量,所以某些模型不适用(例如双塔模型的用户塔是无法获取物品的信息的)
- 局限性:
- 注意力机制的计算量正比于 N(即用户行为序列长度)
- 但是当 N 过小时,模型只关注了用户的短期行为序列和短期兴趣。
- 如何改进DIN?目标是在保障足够长的用户行为序列长度 N 的前提下,确保模型的计算效率。(注意力的计算开销过大)
SIM模型
- 思想:对于DIN模型使用的注意力机制,其中LastN中和候选物品相关度很小(即计算的相似度权重~0)的物品删去也不会有影响。

把 LastN 降低到 TopK 复杂度,输入注意力层。
一个技巧:由于TopK个用户行为特征是具有时间先后信息的,可以将此信息作为特征输入。
- 使用这个技巧的原因:(1)时间越久远的交互信息,其价值越低。(2)相对于DIN模型,SIM模型一般关注的时间跨度更长。
- 使用时间信息作为输入,可以取得很好的收益。

重排:推荐系统的多样性
- 在粗排和精排后需要考虑多样性,提升推荐指标。
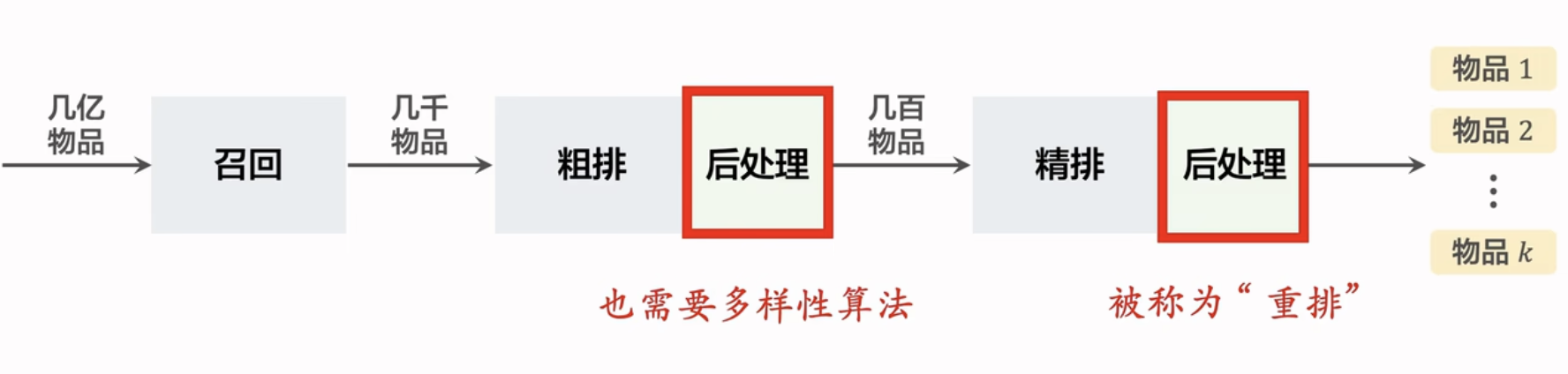
- 重排阶段需要考虑(1)精排阶段的打分分数(2)物品的多样性

相似性度量
如何计算两个物品之间的相似度?
- 基于物品标签的方法:两个物品设置的标签信息。例如美妆、类目、品牌等。
- 基于物品向量的方法:使用学习到的物品的向量,计算余弦相似度等。
- 局限性:使用双塔中的物品塔计算的向量可用性不高,因为其对于长尾物品(曝光少)的学习能力很差。
- 下面提出了一些学习物品向量表征的方法。
基于图文内容的物品向量表征
- 图文内容:例如小红书的笔记包括图片以及文本内容。使用CNN将图片内容转换为向量,使用bert将文本内容转换为向量。
- 大规模预训练:CLIP
- 其中同一篇笔记的图-文是一对正样本(即训练输出图和文的向量越接近越好),不同笔记的图-文是负样本,以此进行大规模的预训练,得到一个笔记的encoder。

Maximal Marginal Relevance[MMR]
- 边缘相关度的计算:实际上是对精排打分以及物品多样性分数的加权,用于迭代选择未选中的物品
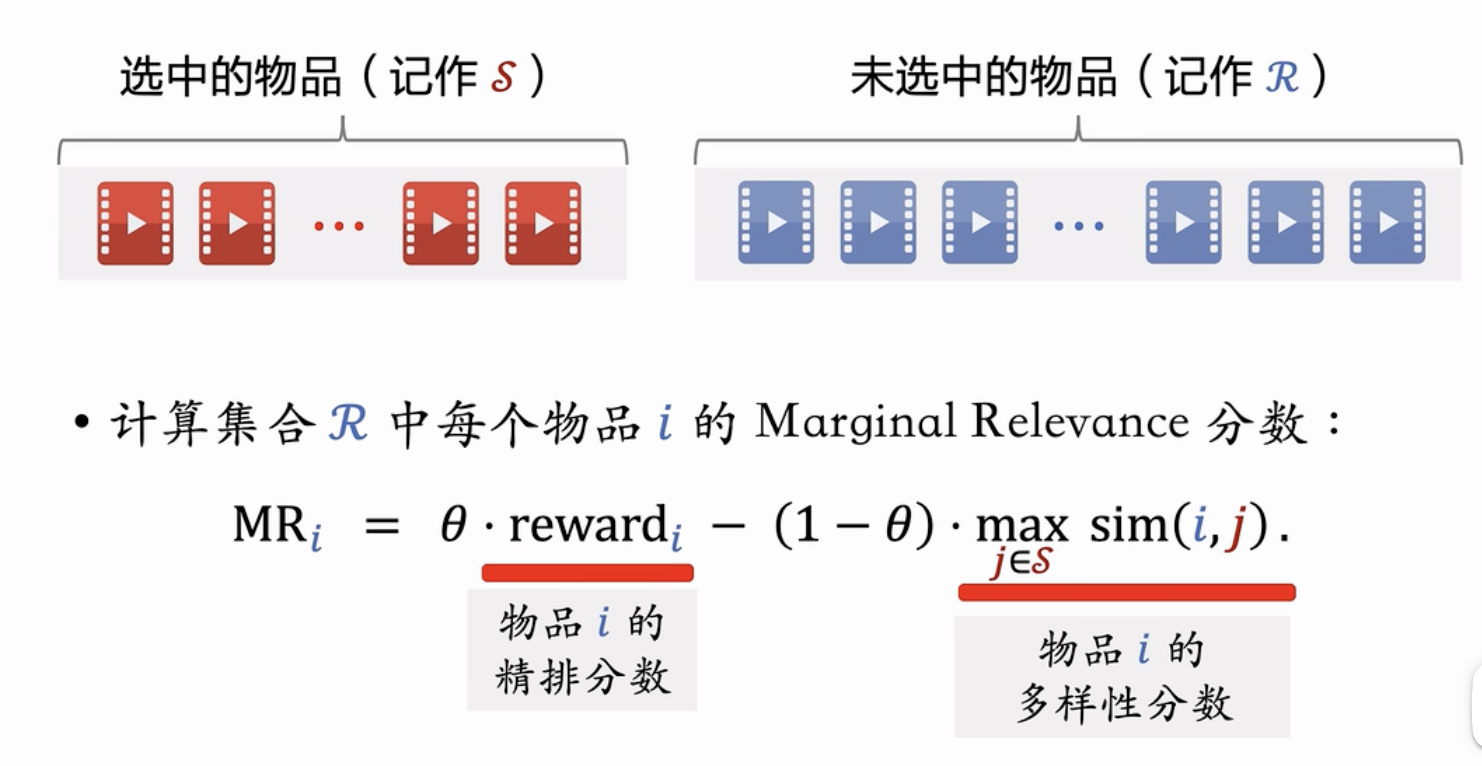
- MMR算法的选择流程:迭代选择MR最高的物品

- 问题?
- 多样性失效:当已经选中的集合物品较多时,使用如上的算法会出现一个问题:即物品总会和某个已选中物品较为相似,即多样性分数趋近于1,使得多样性分数失效。
- 解决:使用滑动窗口的方法,在已经选中的物品进行滑动窗口,只考虑最近一段时间选中的物品

DPP多样性算法
论文🔗Fast Greedy MAP Inference for Determinantal Point Process to Improve Recommendation Diversity
行列式点过程算法(Determinantal Point Process)
推荐阅读:
- 公认的最好的多样性算法
数学基础
(1)将矩阵中的每列看做向量,行列式的几何意义是所有向量张成高维多面体的体积
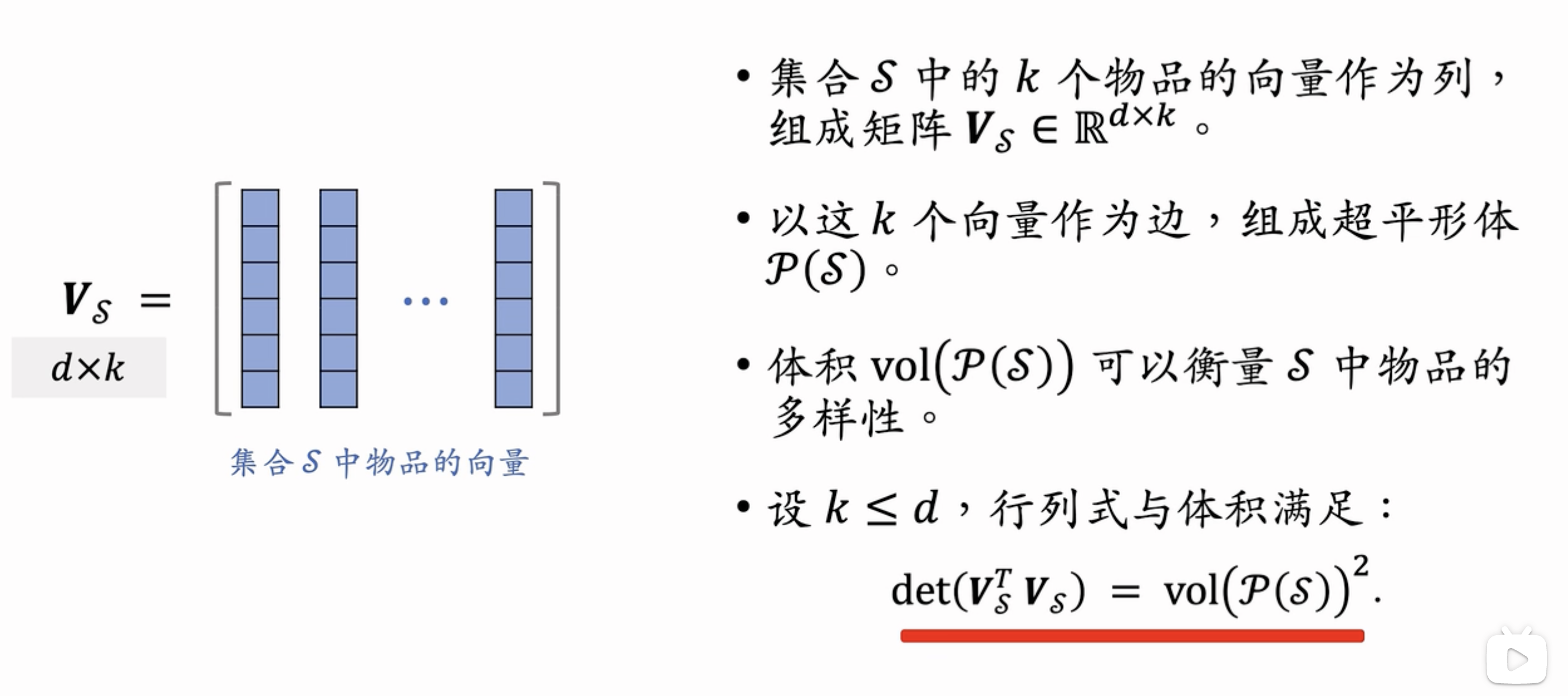
(2)超平行体:向量长成的平行体
DPP在推荐系统的应用
- 如果把不同的商品看作归一化embedding向量,要保障多样性,就要使得其张成的超平行体的体积最大化,而这个体积可以用行列式的计算等价,即使用行列式衡量多样性。

- 加权精排打分以及多样性分数:

DPP快速算法
- 多样性问题是从所有的$n$个待选择商品选出$k$个。
- 矩阵$A$ 是所有n个待选择商品的矩阵,$A_{ij}$是商品i和j的向量内积。

- DPP求解是NP-hard的,一般使用贪心算法进行近似求解,即每一次贪心取出一个最优商品(具有较高的分数,也不能和已经选择的商品相似)。

上述求解的暴力算法的复杂度过高,在实际推荐的过程中多样性选择的时间只有数十毫秒

Hulu的主要贡献是提供了快速的数值算法。

通过每次迭代前后快速求出cholesky分解来快速求解行列式。

物品冷启动
UGC:用户生成内容 ;PGC:平台生成内容
冷启动的评价指标
冷启动的意义:可以为新用户的UGC内容提供曝光,来增强用户体验。
对一个推荐系统冷启动效果是否好的具体的评价指标:

作者侧指标:指的是 笔记发布数量/小红书日活数量,这是评价冷启动的重要指标,有助于促进发布,提高内容池。例如如果推荐算法可以对新笔记提供足够的曝光支持,可以激励发布笔记的作者,增强作者侧指标。
用户侧指标:考虑用户和新笔记的交互率。
内容侧指标:考虑新发布的冷启动的笔记中,高热笔记的占比。这些高热笔记越多表征了系统能够挖掘高质量笔记的能力越强。
主要有两类技术:

冷启动:优化召回通道
- 冷启动物品具有自身特征(例如图片文字标签信息),但是缺少重要的用户交互特征(例如点赞点击),这使得其没有学好ID embedding(ID emb是最重要的召回技术,将笔记的标签嵌入为低维的向量;如果没有ID emb,是无法使用双塔模型进行召回的,双塔是最重要的召回通道);另外,缺少交互信息也无法使用ItemCF技术。
Sol1: 改进双塔模型以适用冷启动
主要的症结在于:冷启动物品的ID embedding没有学到,无法进行物品塔的推荐。
解决:
(1)新笔记统一使用一个默认的embedding向量,相对于使用新笔记自动的ID embedding 可以得到收益。
(2)利用相似的笔记进行embedding,这里的相似可以用:标签类目/图文信息(例如使用CLIP嵌入)进行定义。
Sol2: 使用类目进行召回
- 对每一个用户维护一个感兴趣的类目列表, 例如:情感、程序员、电竞、游戏等等。
- 在系统中维护索引进行召回:

其中笔记列表按时间顺序倒排,有利于新笔记的冷启动。
缺点:
- 窗口期较短:当笔记发布几个小时后,就会被队列往后挤压,导致再也没有机会召回。
- 个性化比较弱。
Sol3: 聚类召回
- 将所有的笔记的embedding向量进行聚类,这样新笔记也可以在聚类空间中根据距离被推荐。

Sol4: Look-Alike召回
在数字营销和广告技术领域,”Look-Alike”(相似受众)是一种用于扩展受众群体的技术。这种方法通过分析现有用户群体的特征,找到与这些用户相似的新用户,从而扩大潜在客户群体。Look-Alike 技术广泛应用于精准营销、广告投放和用户获取等场景。
Look-Alike 的工作原理
定义种子用户群体(Seed Audience):
- 首先,选择一组现有的用户作为种子用户群体。这些用户通常是已经表现出高价值、高互动或高转化率的用户。例如,种子用户可以是已经购买产品的用户、订阅了服务的用户或高频互动的用户。
提取特征:
- 对种子用户群体进行特征分析,提取他们的各种属性和行为数据。这些特征可能包括人口统计信息(如年龄、性别、地理位置)、兴趣爱好、在线行为(如浏览历史、点击记录)以及其他相关信息。
建立相似性模型:
- 使用机器学习算法或统计方法,建立一个相似性模型来识别潜在的 Look-Alike 用户。这些算法可以包括分类算法、聚类算法或推荐系统模型,通过分析种子用户的特征,找到在大数据集中与种子用户相似的新用户。
扩展受众:
- 使用相似性模型在更大的用户数据库中搜索,找到与种子用户群体特征相似的用户。这些相似用户即为 Look-Alike 用户,他们有较高的可能性表现出与种子用户相似的行为和兴趣。
应用 Look-Alike 受众:
- 将 Look-Alike 用户群体应用于广告投放、营销活动和用户获取策略中,以提高广告的精准度和转化率。
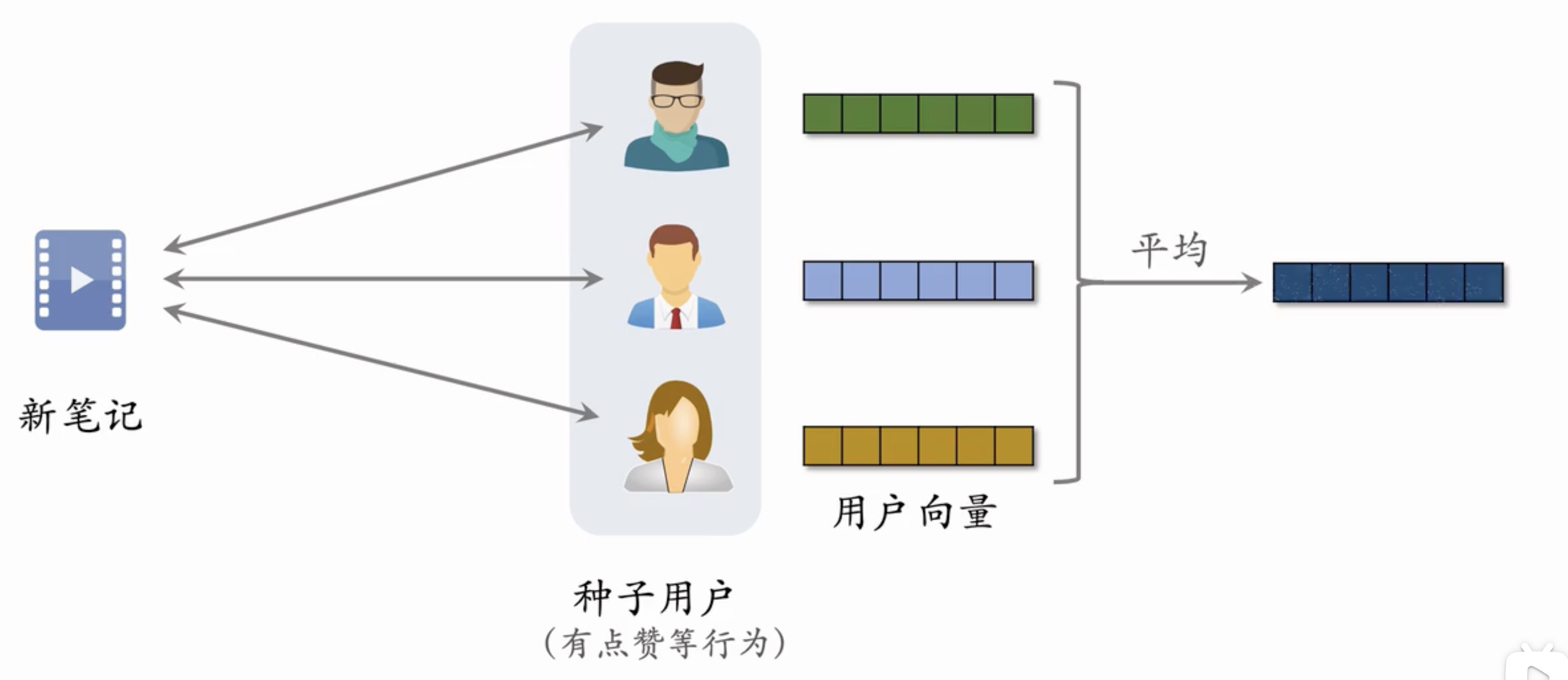
- 把种子用户的向量均值作为物品的向量表征,将该笔记推送给具有潜在的和种子用户类似的用户,可以有效提高笔记的指标。
- 这里维护的向量需要根据时间(种子用户的更新)而实时更新。
冷启动:流量调控

针对上述四种方法:
强插:比较原始的方法。
提权:新笔记的排序分数乘以一个大于一的系数。但是可能存在提权系数难以确定并且敏感的问题。
保量:新笔记在固定时间例如一天之内,必须确保获得一定数量的曝光(差异化保量:越优质的内容保量越高,其中优质可以例如使用多模态模型、作者历史数据等等进行预测)。提权系数可以根据时间和实时曝光数量实时计算。

- 存在问题:如果对新笔记进行保量和提权,可能导致新笔记推荐给不感兴趣的用户,从而导致笔记的点击指标较低,从而被推荐系统打压。所以不能盲目的过度提权。
涨指标的方法
- 推荐系统的核心评价指标?日活用户数 以及 留存

召回阶段:改进
- 为了涨指标,需要改进召回模型,或者添加新的召回模型,其中最重要的召回模型是双塔以及item-2-item
对双塔模型的改进
优化模型的训练样本:例如正样本(成功点击的样本)、简单负样本(随机样本)、困难负样本(排序较为靠后的样本)
改进神经网络结构

- 在用户塔中可以使用用户行为序列作为用户的特征之一(例如last-n交互的均值作为一种特征)。
- 使用更高级的NN,例如DCN。
- 使用多向量模型:在用户塔输出多个向量分别用于不同指标的预测;其中物品塔只输出一个向量,因为其要存入数据库进行搜索,多向量代价会过大。
对Item-to-Item的改进
- 多种I2I模型结合工作,分配一定的配额
- 包括协同过滤等方法
排序阶段:改进
- 对粗排和精排进行改进;
粗精排一致性建模
- 使用精排和实际结果作为标签指导粗排模型

- 可能存在的问题:精排一旦出现问题,会污染粗排。
老汤模型
- 老汤模型是推荐系统部署中的一个难题:即很难判断新模型是否真的比老模型效果好,因为老模型在日益的训练中达到较高的性能;在确定新模型后,需要较长的时间来追上老模型达到的性能

解决?
为了对比新老模型的性能,随机初始化和相同数据下,进行公平对比

为了追平老模型的性能(1)复用一些公用层例如embedding层(2)知识蒸馏

多样性提升
- 加权rank分数以及多样性分数(使用MMR、DPP算法)
- 使用滑动窗口,防止在选择物品过多时,多样性失效。
双塔模型-添加噪声
- 对用户特征添加噪声,使其偏离原有的推荐兴趣域,从而保障多样性。

探索流量
- 维护一个非个性化的、高质量的内容池,将这部分内容强行推送给用户,作为其兴趣的拓展。(如果这部分内容不进行强行提权,是无法通过个性化的筛选的)

多样性总结

特殊用户和人群
例如新用户、低活跃用户(1)这些人用户交互较少,个性化很难做好(2)这些人要着重促使留存,否则易流失
- 构造特殊内容池,用于特殊用户人群的召回。 例如弱个性化的优质内容池。
- 使用特殊排序策略,保护特殊用户。 例如不对这些特殊用户做广告推荐、不推送新物品的测试,这些可能会损害特殊用户体验。另外,可以使用特殊的融分公式,这种推送点击率指标预估高的物品, 吸引特殊用户点击(而忽略其点赞率等指标)
- 使用特殊的排序模型,消除模型预估的偏差。
交互行为
利用关注、转发、评论这三种交互行为给推荐系统涨指标
- 最根本的,可以使用用户的交互率作为标签训练预测模型。
- 交互行为包括:关注、转发、评论等等,利用机器学习模型可以预测出用户对作品的关注率、转发率和评论率,在排序阶段需要着重考虑这几种概率的融分公式。
(1)关注的价值:用户对作者的关注有利于用户留存。所以可以使用模型预测用户的关注率,对关注率较高的内容予以奖励;另外,关注也有利于对作者进行激励,激发起创作积极性。
(2)转发的价值:转发可以吸引应用的站外流量。外站的KOL(key opinion leader,即大V)的转发价值最大,所有需要着重关注(可以通过历史的转发流量收益来判断作者是否是外站的KOL)。
(3)评论的价值:和关注类似。
- 对于不同的用户,可以设置不同的融分公式,来推送针对性的内容。例如,外站KOL需要被推送高转发率的内容,促使其转发;高质量评论用户需要被推送高评论率的内容,促使其留下高质量评论。
——————————————————————🌹🌹🌹 ENDING 🌹🌹🌹—————————————————————————————