RecSys-Pipeline
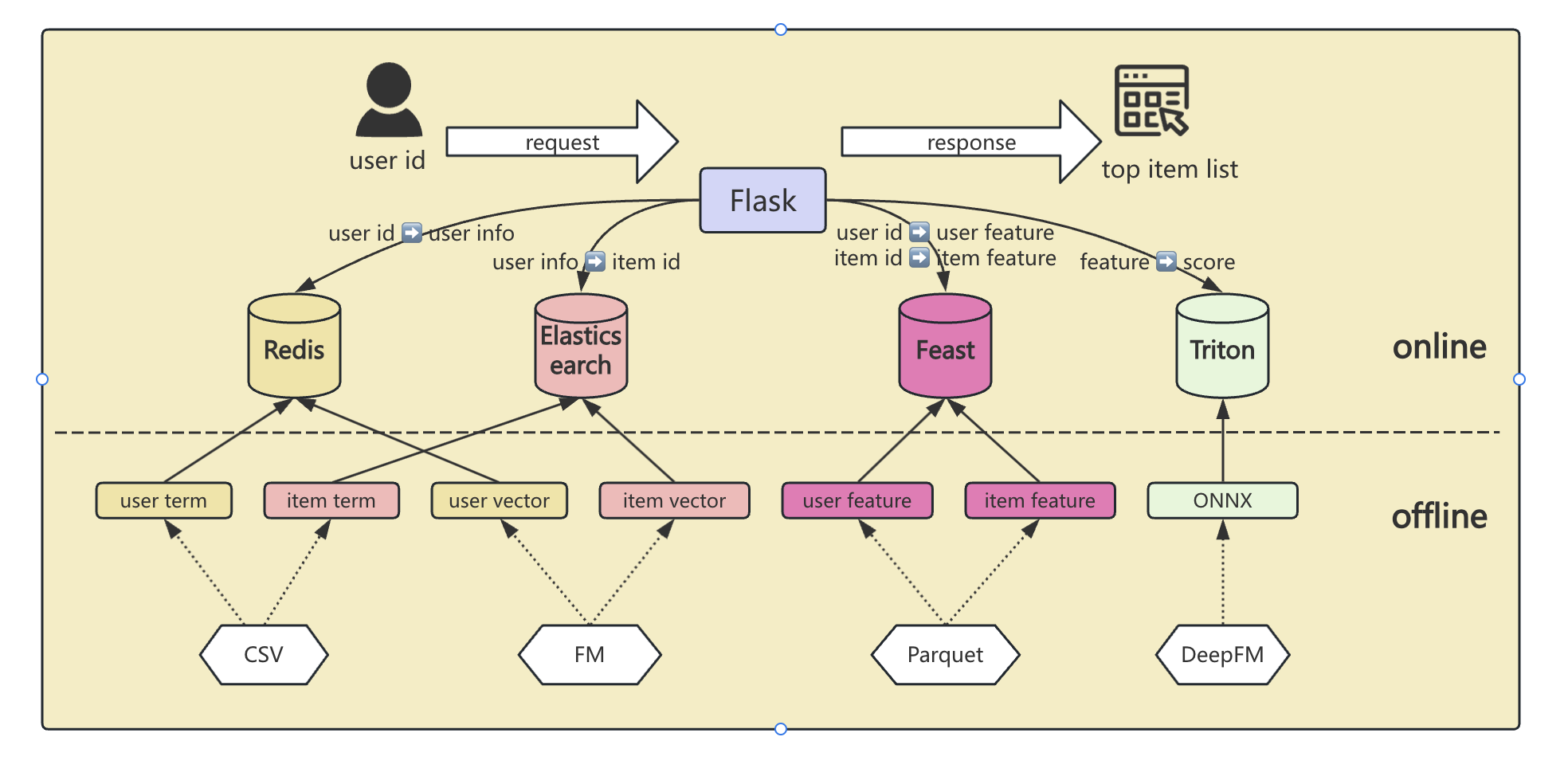
全流程推荐系统
项目需要把细节搞清楚,即为什么这么做
项目背景:基于经典的MovieLens数据集,设计并实现的一个离线到在线的推荐系统。在单机环境下实现了推荐系统的完整流程,成功将离线数据处理、模型训练、特征存储、实时推荐打分模块集成在一个系统内。
这个系统显然是包含offline、online、offline to online(即使用离线训练好的数据对在线模型进行更新)三个部分
离线阶段使用Pandas和PyTorch模拟工业界HDFS/Spark/GPU集群的大规模数据处理与深度学习模型训练流程。
在线阶段通过Docker调用多个微服务组件,包括Redis(用于用户标签与向量存储)、Elasticsearch(实现基于倒排索引和向量检索的候选召回)、Feast(进行特征存储和管理)和Triton(使用 DeepFM 模型对特征进行实时打分和排序),模拟工业界Spring推荐后端的RPC调用流程。
什么是微服务组件?什么是微服务?
- 微服务(Microservices)是一种软件架构风格,它将一个应用程序分解为多个小型、独立的服务,每个服务只负责单一的功能或业务能力。这些服务可以独立开发、部署、扩展,并通过轻量级的通信协议(通常是HTTP/REST API)进行互相通信。
四个框架(redis、es、feast、triton是什么?原理?使用?)
单机环境下实现了推荐系统的完整流程,成功将离线数据处理、模型训练、特征存储、实时推荐打分模块集成在一个系统内。
MovieLens数据集
- 推荐系统领域最为经典的数据集之一,其地位类似计算机视觉领域里的MNIST数据集。
- 文件解压之后,可以得到4个文件
- movies.dat 电影的相关信息,即电影id、电影标题、电影类型
- user.dat 用户的相关信息,包括性别、年龄、职业
- ratings.dat 用户id、电影id、该用户对此电影的评分、时间戳。每个用户至少会对20部电影进行评级。
- README
在线推理流程(online)
使用redis进行user info存储;
使用es进行召回(两条通道:(1)使用user-term即用户的偏好电影类型进行召回(2)使用user-vector和item-vector进行knn召回;)
使用feast进行特征存储(通过id返回特征)
feast的特殊性在哪里?为什么不使用redis进行id->feature的过程?
使用 triton inference server 进行模型推理。
特征类型
在推荐系统中,特征通常分为稀疏特征(sparse features)和稠密特征(dense features)。
offline-to-online端
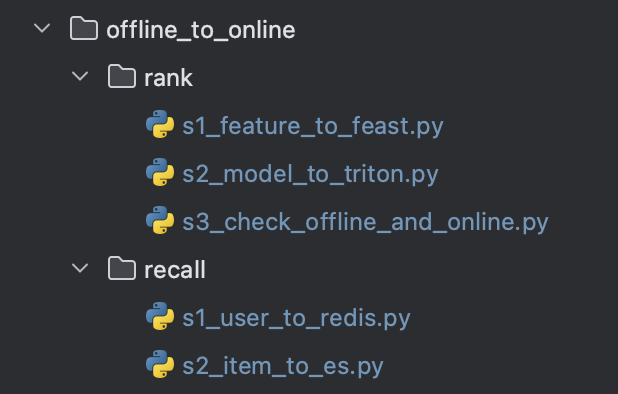
- 由于online端是实时的,要在offline一侧对online需要的数据进行更新
recall阶段:
(1)对redis中的user信息进行维护;(从data_exchange_center.paths中取出数据并插入redis)
(2)对es中的item信息进行维护;(创建index、删除现有的数据、插入最新的数据)
es的具体原理和用法看黑马的视频,并写作博客;
rank阶段:
- (1)对feast中的feature信息进行维护;
- (2)对triton中的模型信息进行维护(使用torch.onnx.export的方法将模型导出为onnx格式);
- (3)分别使用offline模型以及online模型(即在triton部署的推理模型)对同一批样本进行推理,验证部署的有效性;
offline端
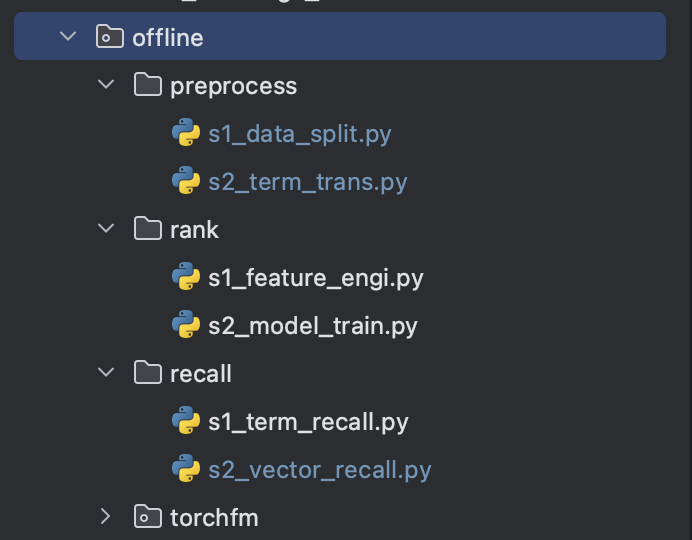
- 包括预处理、离线recall、离线rank三个部分;其中torchfm是pytorch提供的机器学习模型包
recall阶段:
在racall的offline部分主要负责:生成es所需要的item/user vector以及term
其中vector-recall部分:使用MF(矩阵分解)模型进行训练;构建user矩阵P以及item矩阵Q;使用实际的评分训练集对嵌入矩阵P和Q进行训练;
虽然叫做MF模型,但是并没有实际的使用矩阵分解;而是通过对P和Q矩阵进行Xavier初始化,然后使用训练数据进行迭代训练;
最后的AUC(使用测试集的预测成功概率的ROC)达到0.81,性能相对优秀;
rank阶段:
在rank的offline部分负责
(1)生成feast所需要的user/item feature,这部分需要详细的特征工程;
(2)进行rank模型(DeepFM)的模型训练;
DeepFM
论文链接:DeepFM: AFactorization-Machine based Neural Network for CTR Prediction
- 结构/原理效果
数据交换中心
- 数据的统一集成:整合来自不同来源(如用户行为日志、物品特征、外部数据源等)的数据
- 数据的统一存储和标准化
- 有利于实时数据流动
如何召回?
- 在实时online的召回阶段:主要通过(1)倒排索引(2)向量检索
如何排序?
- 通过deepfm模型对特征的相似度进行打分,排序;
技术选型
Flask Web框架:
Python常用的web框架有Django, Flask, FastAPI, Tornado等,都可以实现REST API请求 -> url路由到某个函数 -> 处理的逻辑,各有优缺点,随机选取了Flask 。这里使用Python作为后端仅仅是因为环境安装方便,工业界的推荐系统一般会使用Java + SpringBoot或者Go + Gin作为web后端。
Triton 全称是Triton Inference Server,是Nvidia开源的全模型serving引擎,支持TensorFlow、PyTorch、ONNX和其他各种模型,虽然是N家的产品,但是也可以使用cpu进行serving,所以请放心使用。业界更通用的方案是TensorFlow -> SavedModel -> TF Serving,但Triton因为不会被绑定在一家平台上,个人非常看好它的前景,所以这里使用的是PyTorch -> ONNX -> Triton Server的方案。
Elasticsearch 的大名也是无人不知,我们使用它来为item构建倒排索引和向量索引。它最初被用于搜索领域,最原始的用法是用word去检索doc,如果我们将一个item视为一篇doc,它的标签(如电影类别)视为word,就可以借助ES来根据标签检索item,这就是倒排索引的概念,因此Elasticsearch也常被用于推荐系统的term召回模块。对于向量召回,经典工具是facebook开源的faiss,但是为了方便整合,我们在这里使用Elasticsearch提供的向量检索功能,Elasticsearch自版本7开始支持向量检索,版本8开始支持近似KNN检索算法,这里我们安装的是8及以后的版本,因为精确KNN检索的性能几乎不可能满足线上使用。
项目创新点
+