Python基础
- 本科阶段系统学过C、C++,自学过Go,但是Java和Python都没有系统的学过或是自学过。
- 深度学习对Python编程的要求比较大,所以还是得系统的过一遍Python的基础语法和相关用法,并将一些容易遗忘的知识点或者是比较好的阅读内容Ping在这篇博客中,用于记录和温习。
- 遇到不懂的内容随时记录。
学习内容
Python 是一种解释型语言
- C++代码需要一个编译的过程,全部编译为机器码后执行;
- Python具有即时的解释运行的能力,解释一行运行一行
- 跨平台兼容特性:只需要相应的Python解释器;
- 性能较低,低于编译型语言;
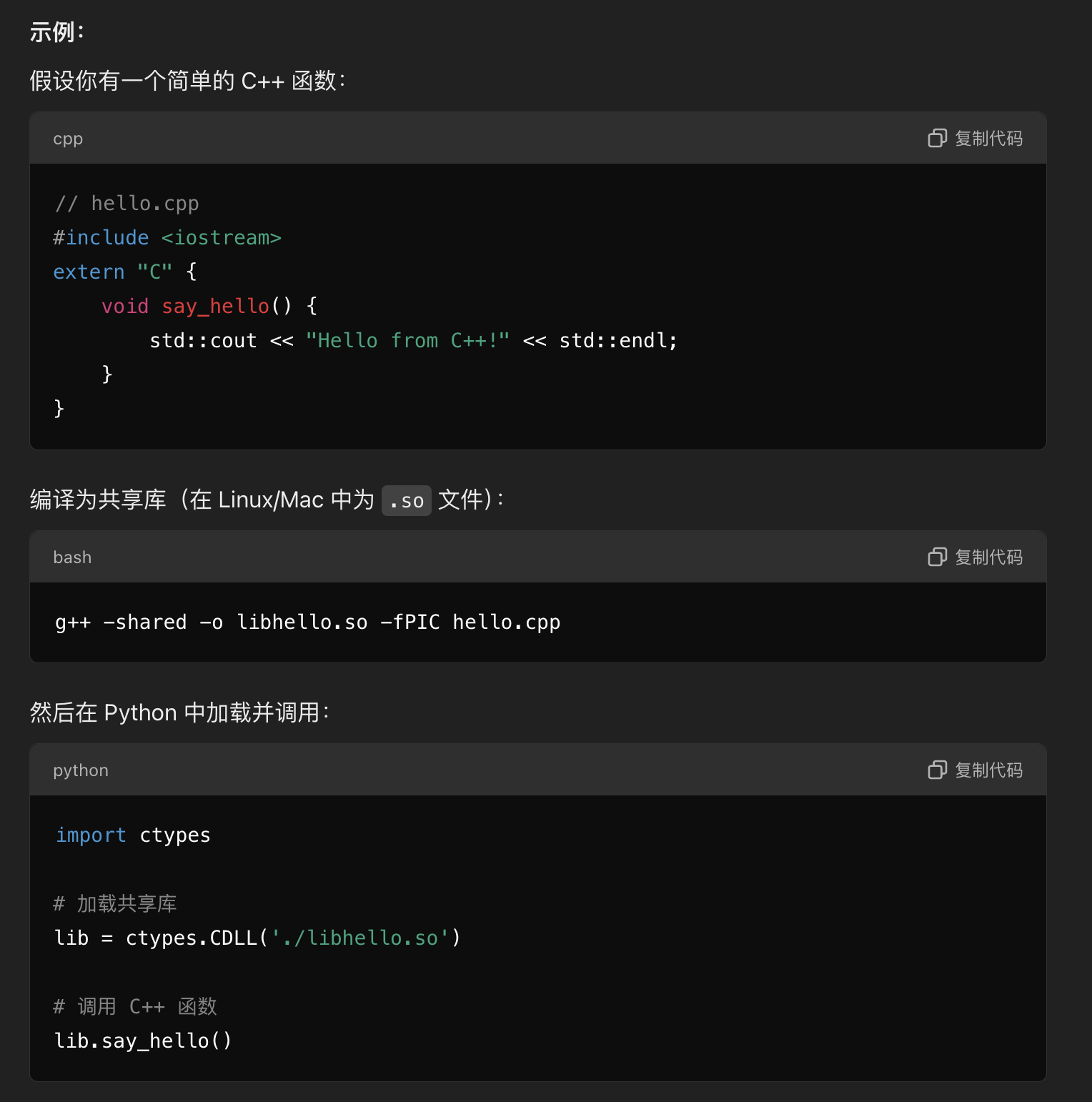
Python 中如何调用 C++ 代码
- 将c++代码编译为共享库(so文件),然后通过ctypes加载并调用
使用Cython:
Cython是一种编程语言,是python的超集,同时融合了C++的静态类型特性;
Cython是一个用于将 Python 和 C/C++ 代码无缝集成的工具。你可以通过Cython编写 Python 和 C++ 混合代码,或者直接调用现有的 C++ 函数库。步骤:
- 用
Cython编写接口代码,使 Python 可以调用 C++ 函数。 - 使用
Cython编译并生成 Python 可调用的扩展模块。
- 用
什么是CPython、JPython
- CPython是Python的解释器的一种实现,而Cython是一种编程语言(融合了Python以及C++的特性);
- 标准解释器 CPython 是由 C 语言实现的,除了 CPython 之外还有 Jython(java实现的 Python 解释器)、PyPy(Python 语言实现的 Python 解释器)
Python 是一种动态类型语言(指在运行期间才去做数据类型检查的语言),这意味着变量的类型是在运行时确定的
- 在 Python 中,变量并不是存储实际的值,而是存储对象的引用。可以理解为,Python 中的变量是指向对象的指针,指向的对象包含了实际的数据和值。
1 | x = 42 # x 是指向整数对象 42 的引用 |
Python的垃圾回收机制
- 主要依赖于 引用计数 和 垃圾回收器(GC)
引用计数是 Python 管理内存的基本机制。当一个对象被创建时,Python 会给这个对象分配内存,并为该对象的引用计数设置为 1。每当有一个新的引用指向该对象时,引用计数增加;当一个引用不再指向该对象时,引用计数减少。
引用计数的工作方式:
增加引用计数:当一个新变量引用该对象时。
1
2a = [1, 2, 3] # 列表对象的引用计数为 1
b = a # 列表对象的引用计数增加到 2减少引用计数:当一个引用不再指向该对象时(如使用
del删除变量,或者变量指向了其他对象)。1
2del a # 列表对象的引用计数减少到 1
b = None # 列表对象的引用计数减少到 0,触发垃圾回收对象销毁:当对象的引用计数降为 0 时,Python 立即释放该对象占用的内存。
具体来说,有如下的引用计数的方法:

引用计数的优势:
- 简单高效,当引用计数为 0 时,Python 可以立即释放内存。
- 实时性强,内存回收可以即时发生。
引用计数的局限:
循环引用问题:如果对象之间相互引用,则即使没有其他变量引用这些对象,它们的引用计数也永远不会归零,导致无法被销毁。这种情况下,单靠引用计数是无法解决的。
1
2
3
4
5
6
7
8
9class Node:
def __init__(self):
self.other = None
node1 = Node()
node2 = Node()
node1.other = node2
node2.other = node1
# node1 和 node2 之间形成了循环引用,它们的引用计数不会降为 0
为了解决引用计数无法处理循环引用的问题,Python 还引入了一个 垃圾回收器(GC),它专门处理循环引用。
Python 的垃圾回收器如何工作:
Python 的垃圾回收器采用的是 分代收集 算法,它将对象划分为三代:
- 第一代(Generation 0):新创建的对象。
- 第二代(Generation 1):经过一次垃圾回收未被销毁的对象。
- 第三代(Generation 2):经过多次垃圾回收仍未被销毁的对象。
垃圾回收器会定期对第一代对象进行检查。如果发现某些对象形成循环引用,且无法通过引用计数回收,它会标记这些对象并进行内存回收。通常,对象越老,越有可能继续存在,因此垃圾回收的频率对高代对象较低,对新生对象较高。
垃圾回收器的工作流程:
- 标记-清除(Mark-and-Sweep)算法:垃圾回收器会遍历所有的对象,将可达的对象标记为 “活跃”。未被标记的对象则会被认为是垃圾,最终被销毁。
- 分代回收:新创建的对象通常有较高的可能性很快就会被销毁,因此垃圾回收器主要针对新对象(第一代)进行回收,而较老的对象(第二代和第三代)被认为是长期存在的对象,回收频率较低。
Python的常用数据结构
- 列表、元组、字典
- 这些常见的操作直接看菜鸟教程,都写的比较详细了;
对比列表和元组
| 特性 | 元组(Tuple) | 列表(List) |
|---|---|---|
| 可变性 | 不可变 | 可变 |
| 语法 | 圆括号 () |
方括号 [] |
| 用途 | 固定数据集合 | 动态数据集合 |
| 性能 | 访问速度更快 | 访问速度稍慢 |
| 哈希性 | 可哈希(可作为字典键) | 不可哈希 |
| 存储空间 | 占用空间更小 | 占用空间较大 |
主要:
元组是不可变的:元组一旦创建,不能修改其中的元素。也就是说,不能对元组中的元素进行增、删、改操作。
列表是可变的:列表中的元素可以随时修改,支持增、删、改操作。
元组的不可变性使它更安全:如果一个对象不希望在程序的其他地方被修改,可以使用元组,提供了更多的安全性。
元组是可哈希的,因此可以作为字典的键或集合中的元素(前提是元组中的所有元素也是可哈希的)。
列表不可哈希,因此不能作为字典的键或集合中的元素。