大数据框架
- 主要是 Hadoop(Hive)以及 Spark 的学习,用于大数据、数据挖掘、推荐系统等岗位的工程技能;
- 大数据教程:大象教程
Spark
什么是 Spark?
- Apache Spark 是一个开源的分布式计算框架,专门用于大规模数据处理。
- Spark 的设计目标是提供一种能够在分布式环境中高效处理大数据的计算引擎,并且具备比传统 MapReduce 更快的执行性能。
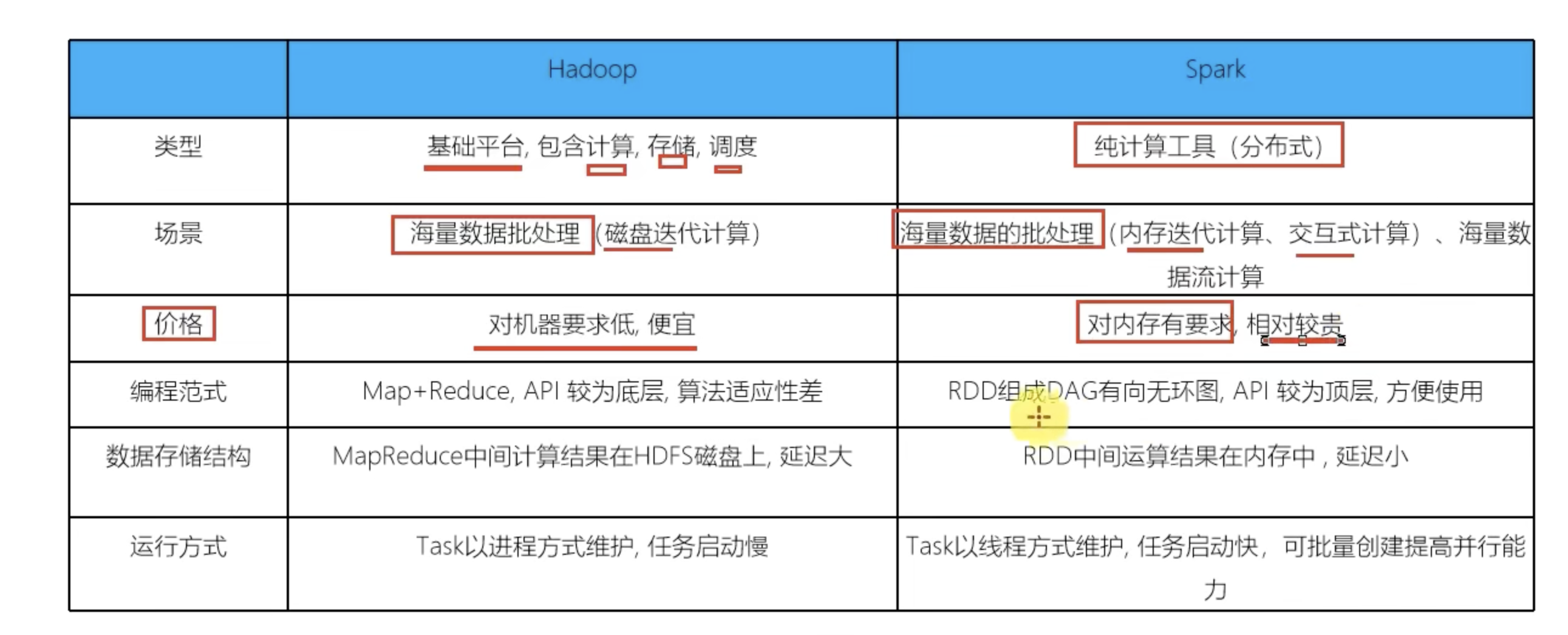
和Hadoop的区别和联系?
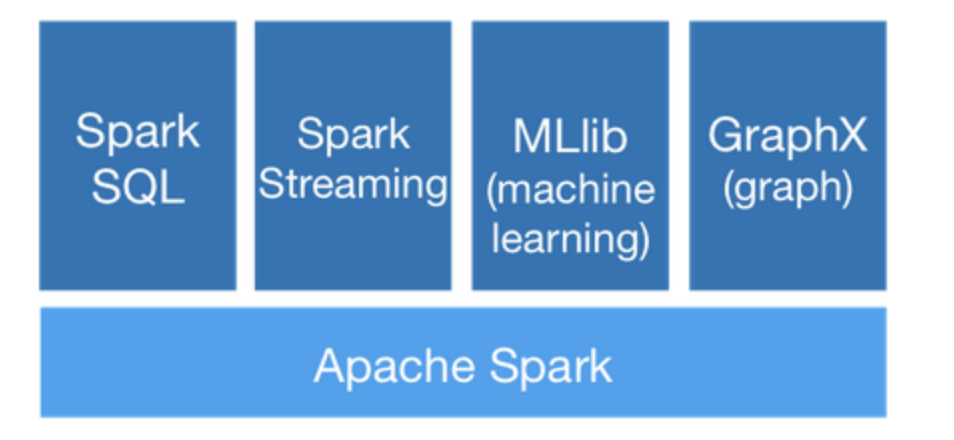
Spark组件
- Spark Core:将分布式数据抽象为弹性分布式数据集(RDD),实现了应用任务调度、RPC、序列化和压缩,并为运行在其上的上层组件提供API。所有Spark的上层组件(如:Spark SQL、Spark Streaming、MLlib、GraphX)都建立在Spark Core的基础之上,它提供了内存计算的能力,因此,Spark Core是分布式处理大数据集的基础。
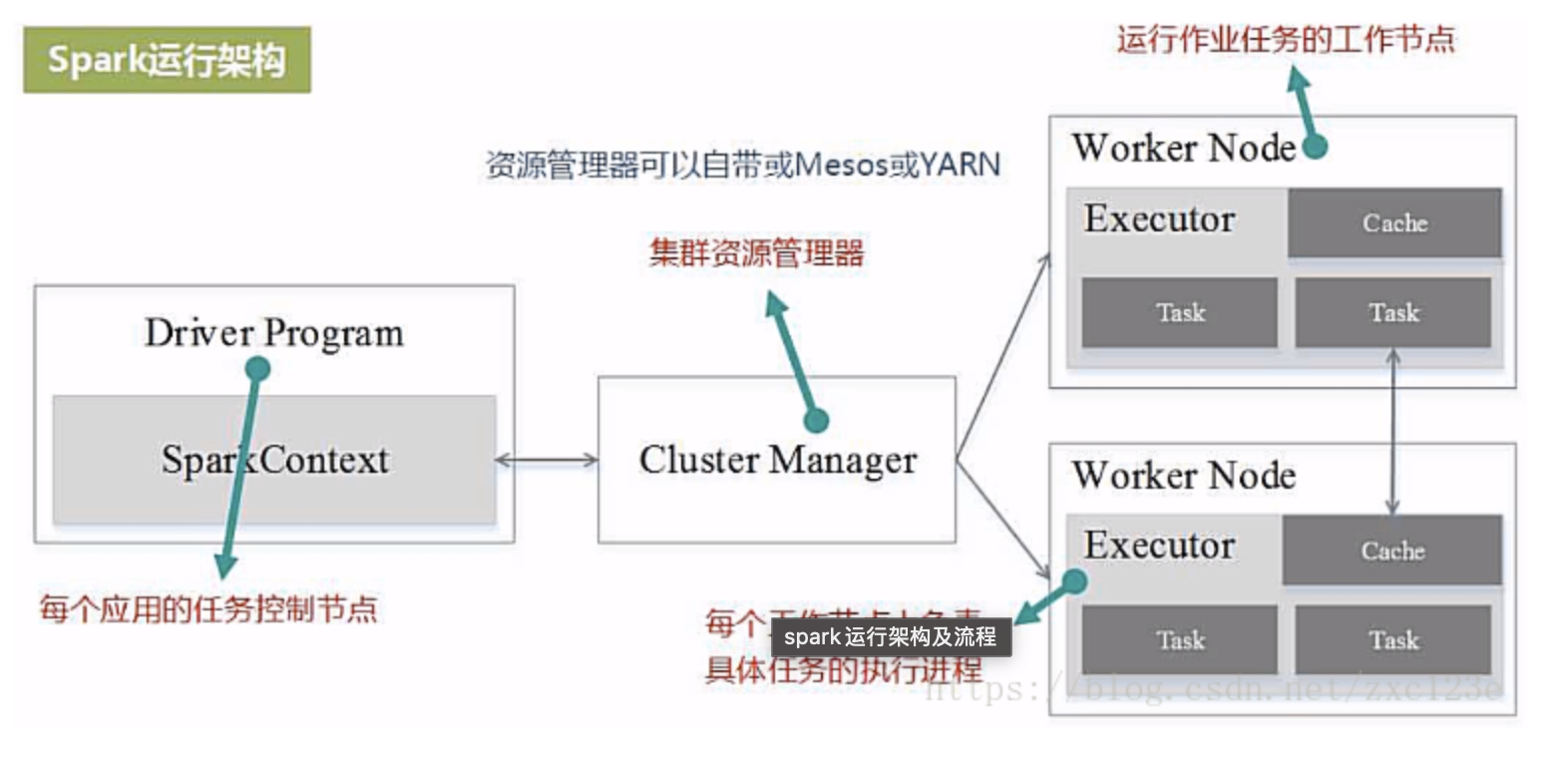
Spark 基本架构
- Apache Spark 的基本架构是一个基于主从结构(Master-Slave)的分布式计算架构
Application
- 用户编写的Spark应用程序,包含了driver程序以及在集群上运行的程序代码,物理机器上涉及了driver,master,worker三个节点。
1. Driver(驱动程序)
- Driver 是 Spark 应用程序的主控程序,它负责与集群交互、任务的分配和调度。Driver 会创建一个 SparkContext(或在 Spark 2.x 中为 SparkSession),并通过 SparkContext 来与集群交互。
- Driver 程序负责将用户的作业拆分为多个任务,将这些任务分发到集群的 Executor 节点,并跟踪任务的执行状态和结果。
- Spark中的Driver即运行Application的main函数并创建SparkContext,创建SparkContext的目的是为了准备Spark应用程序的运行环境,在Spark中由SparkContext负责与Cluster Manager通信,进行资源申请、任务的分配和监控等,当Executor部分运行完毕后,Driver同时负责将SparkContext关闭。
2. Cluster Manager(集群管理器)
Cluster Manager
是 Spark 与底层集群之间的桥梁,负责管理集群中的资源。Spark 支持多种集群管理器:
- Standalone:Spark 自带的资源管理器。
- YARN:Hadoop 的资源管理框架。
- Mesos:另一种分布式资源管理系统。
- Kubernetes:用于容器化和云原生环境的资源管理。
Cluster Manager 负责在集群中为 Spark 应用程序分配 Executor 进程。
3. Executor(执行器)
- Executor 是运行在每个工作节点上的进程。每个 Executor 负责执行由 Driver 分配的任务,并为每个任务提供运行的上下文环境。
- Executor 的主要职责:
- 执行 Driver 分配的任务。
- 将计算结果和数据返回给 Driver。
- 在内存中缓存数据以供后续使用(如果指定了持久化)。
- 每个 Spark 应用程序都会拥有自己独立的 Executor,且这些 Executor 在应用程序执行期间一直保持存活。
4. Worker(工作节点)
- Worker 是集群中的物理或虚拟机器节点,负责运行 Executor 进程。集群中的每个 Worker 负责管理和监控 Executor 的运行状态。
5. Tasks(任务)
- Task 是 Spark 的最小计算单元,是针对分区的数据执行的具体计算操作。Driver 会将作业(Job)拆分为多个阶段(Stage),每个阶段再进一步拆分为多个 Task。Task 由 Executor 进程执行。
Spark运行基本流程
+
SparkContext
+
Spark RDD(Resilient Distributed Dataset)
核心数据结构-弹性分布式数据集
特性:
- Resilient(弹性):RDD之间会形成有向无环图(DAG),如果RDD丢失了或者失效了,可以从父RDD重新计算得到。即容错性。
- Distributed(分布式):RDD的数据是以逻辑分区的形式分布在集群的不同节点的。
- Dataset(数据集):即RDD存储的数据记录,可以从外部数据生成RDD,例如Json文件,CSV文件,文本文件,数据库等。
什么是 PySpark?
Spark的DAG是什么?
数据抽象:RDD
Spark的运行模式:本地单机/集群/云

Spark 的架构角色
Master/Worker (资源管理层面)
Diver/Executor(单任务层面)
Spark环境搭建
Apache Spark 的进程实际上是运行在 Java 的 JVM (Java Virtual Machine) 上的。Spark 本身是用 Scala 编写的,而 Scala 运行在 JVM 上。因此,无论你用什么语言(Scala、Java、Python、R)编写 Spark 应用程序,Spark 都会在底层启动 JVM 进程来执行你的代码。
Python + Spark + JDK